2.4 Graphiti / Mem0 / Cognee / LightRAG
资料库的下一层不是再多塞一个向量库,而是记忆和关系:让智能体 记住老板的偏好和项目历史,让检索能沿着实体边走,而不是只看相似度。这一页把四个候选工具按用途拆开,并说明为什么它们都被压到二期之后。
相关来源文件
docs/11-reference-platforms-agentic-knowledge-base.md· §7 Memory & Graph (Graphiti / Mem0 / Cognee / LightRAG)。
为什么把这四个放一起
它们都不是文档管理或 RAG 编排,而是处理跨次对话的状态和实体之间的关系:
- Graphiti / LightRAG 偏图:把抽出的实体和关系组织成图,检索时沿边走。
- Mem0 / Cognee 偏记忆:把用户、Agent、会话维度的事实沉淀下来,下次对话能用。
- 四者都不取代向量库,而是叠在向量库 / 文档库之上,回答"上次的事"和"和谁有关"。
本项目的判断
一期已经够忙:实体 / 字段 / 权限 / 标签 / Argilla 回流。这一层在一期完全没有位置,强行上等于在还没干净的数据上盖图,越盖越脏。
四个项目对照
| 项目 | 定位 | 核心能力 | 对接方式 | 本项目阶段 |
|---|---|---|---|---|
| Graphiti | 面向 人工智能体 的时序知识图谱 | 增量更新节点 / 边;事实带时间戳,支持"何时成立 / 何时失效";混合语义 + 关键词 + 图检索;MCP server 暴露给 Agent | MCP / SDK,写入实体与事实,查询走图 + 向量混合 | 三期:项目历史跟踪 / 老板助理长期记忆 |
| Mem0 | 人工智能体 / 助理的记忆层,自托管或托管平台 | user / agent / session 三维记忆;自动抽取偏好与事实;可选向量存储后端 | SDK 包在 智能体调用前后,自动 add / search memory | 三期(老板助理方向) |
| Cognee | AI 记忆控制面,remember / cognify / search 生命周期 | 原始资料 → 抽取实体关系 → 写入图 + 向量;面向 智能体的语义记忆 | Python SDK / MCP,作为离线 cognify 流水线 + 在线 search | 二期后段到三期:评估能否替代自研图抽取 |
| LightRAG | 轻量级 图谱增强检索 框架 | 索引阶段抽实体关系建图,检索阶段沿图走 + 向量召回;本地 / 多后端可选 | 独立服务或库,喂入文本块,问答时走 图谱增强检索 | 二期验证:政策 / 合同跨文档关系检索 |
来源
docs/11-reference-platforms-agentic-knowledge-base.md §7。
Code
getzep/graphiti ·
时序图核心
graphiti_core/graphiti.py(add_episode / search);
节点 / 边模型 graphiti_core/nodes.py、graphiti_core/edges.py;
混合搜索 graphiti_core/search/;
MCP server mcp_server/。
Code
mem0ai/mem0 ·
记忆主控
mem0/memory/main.py(add / search / update / delete);
embedder / vector store / graph store 抽象 mem0/embeddings/、mem0/vector_stores/、mem0/graphs/;
LLM 适配 mem0/llms/;
配置入口 mem0/configs/。
Code
topoteretes/cognee ·
remember / cognify / search 三段 接口
cognee/api/v1/(add/、cognify/、search/);
pipelines 与 tasks cognee/modules/pipelines/、cognee/tasks/;
数据模型与图层 cognee/modules/data/、cognee/modules/graph/;
MCP 集成 cognee-mcp/。
Code
HKUDS/LightRAG ·
索引 / 检索主类
lightrag/lightrag.py;
插入与查询算子 lightrag/operate.py(extract_entities / kg_query / naive_query);
存储后端抽象 lightrag/kg/(Neo4j / Postgres / NetworkX);
Server 端 lightrag/api/。
两条轴:图 vs 记忆,离线 vs 在线
| 偏离线索引(cognify) | 偏在线请求(智能体运行时) | |
|---|---|---|
| 偏图(实体关系) | LightRAG · Cognee | Graphiti |
| 偏记忆(用户/会话事实) | Cognee | Mem0 · Graphiti |
四者并不互斥:可以用 LightRAG / Cognee 在离线把资料图建出来,用 Graphiti 承载在线增量事实和时间维度,用 Mem0 承载老板助理的个人偏好。
分期时间线
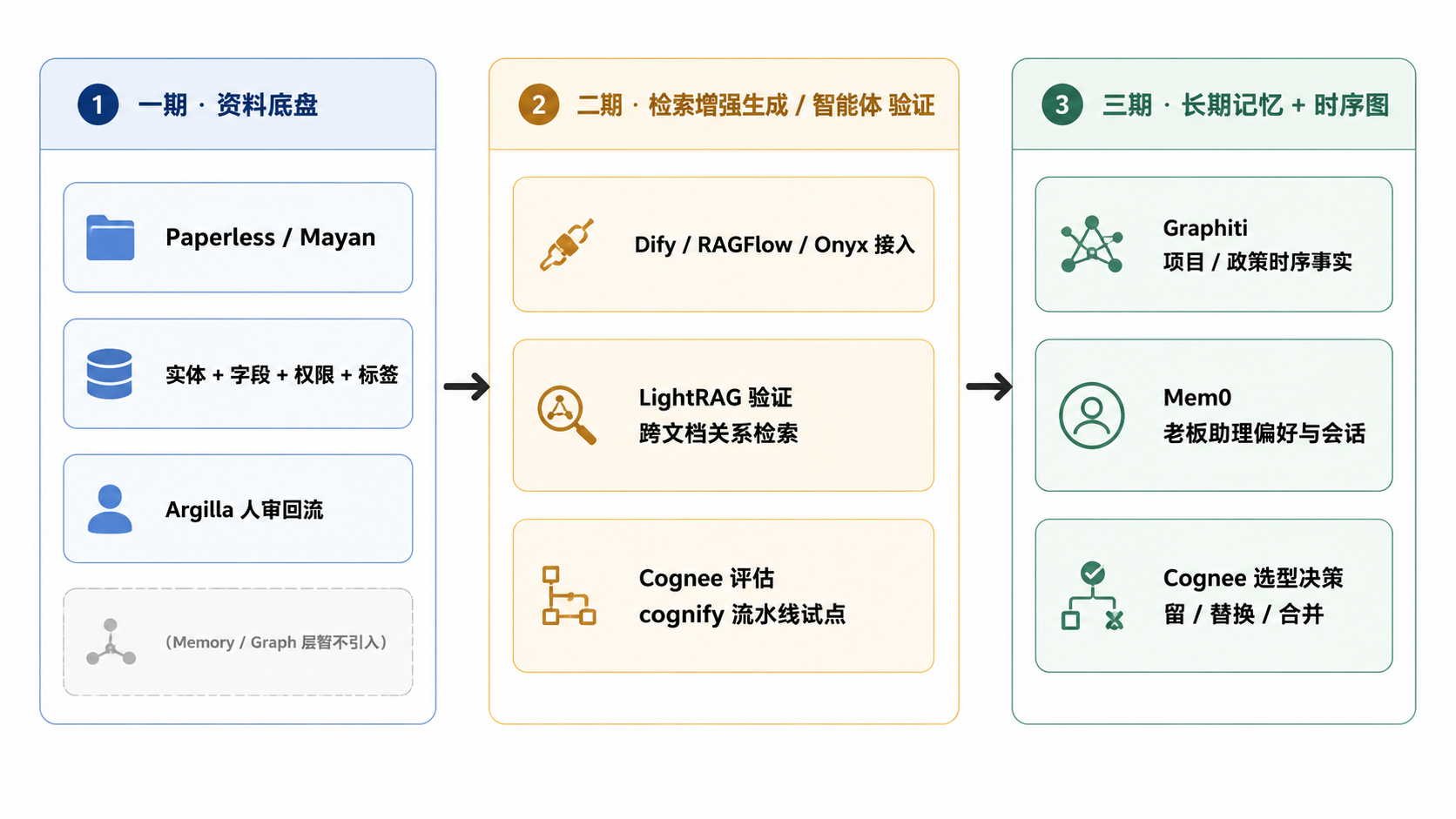
图 2.4.1 · 一期不引入,二期做 LightRAG / Cognee 验证,三期把 Graphiti + Mem0 接进老板助理与项目跟踪。
为什么不压到一期
三个原因,按因果顺序:
- 没有稳定的实体 / 字段 / 权限,图就是噪声。 Graphiti / LightRAG 抽取的节点和边,最终要落到客户、合同、项目、政策这些实体上。如果一期连
customer_id和policy_id都还没收敛,图里全是字符串重名节点,越增量越乱。 - 没有稳定的检索,智能体记忆就是幻觉的复读机。 Mem0 把对话事实写下来,下次取回。如果底层 检索增强生成链路还在波动、引文还不准,写进 memory 的"事实"会把错误固化,下次还会再用。
- 多一层就多一层运维。 图库(Neo4j / FalkorDB / Memgraph)+ 记忆服务 + MCP server,对一期"先把资料管起来"是纯负担。
原则
图和记忆都是放大器:底层数据干净,它们放大价值;底层数据脏,它们放大错误。所以顺序固定为 资料底盘 → 检索增强生成 / 智能体 → 记忆 / 图,不可颠倒。
三期落地场景
| 场景 | 主要诉求 | 建议工具 | 说明 |
|---|---|---|---|
| 老板助理 · 会前简报 | 记住老板偏好(关注哪几类指标 / 不喜欢哪种汇报方式 / 常问什么) | Mem0 | 用户维度 = 老板,智能体维度 = 助理;每次会议前检索记忆并拼入提示词 |
| 项目历史跟踪 | 同一个项目跨年度的合同 / 政策 / 决议 / 关键人,事实有时效 | Graphiti | 时序事实正是 Graphiti 的强项;项目节点连合同 / 政策 / 人,边带 valid_from / valid_to |
| 跨政策关系检索 | "和这条新政策相关的旧文有哪些 / 哪条被废止" | LightRAG(二期验证)→ Graphiti(三期增量) | 离线用 LightRAG 把存量政策建图,三期把增量切到 Graphiti 维护时效 |
| 智能体长期上下文 | 跨多次会话保留任务进度、已确认结论、未决事项 | Mem0 + Graphiti | Mem0 管"我和这个智能体 之间的事",Graphiti 管"项目级共享事实",两层不互相覆盖 |
来源
docs/11-reference-platforms-agentic-knowledge-base.md §7。风险与边界
- 不要把图当唯一真相。 实体真相在 PostgreSQL(一期建好的事实表);图是关系视图,靠同步任务从事实表派生,可重建。
- 记忆要可遗忘。 Mem0 写入的事实需要带 TTL / 失效条件,并允许"忘记某条",否则会把过期偏好固化。
- 抽取错误要能回滚。 Cognee / LightRAG 自动抽出的实体关系,必须保留 source 文档与置信度,可以批量撤回某次 cognify 的结果。
- 权限不能在图层重新发明。 图查询返回前,必须按一期定义的权限过滤节点和边,不能因为"图里有"就让智能体 看见。