2.5.12 LongParser
LongParser 适合补齐现有 RAGFlow 之外的“LangGraph 编排 + 长文档抽取 + 人工复核”样本。它不替代 RAGFlow,也不进入一期事实源,只用于对照复杂合同、制度、会议纪要等长文档的解析任务拆分方式。
业务需求长文档解析、结构化抽取与人工校验
架构位置文档理解层的算法验证样本,位于 SVN 只读采集之后、结构化索引之前。
落地阶段二期算法验证 / 补充参考
译文库范围
本项目不属于当前 DeepWiki 中文译文库范围;本页保留项目定位、可迁移机制与落地要点。业务问题与适用场景
企业资料知识中枢里最难稳定处理的资料往往不是短 FAQ,而是长合同、投标文件、项目制度、跨页表格和多层标题文档。LongParser 的价值在于把长文档解析拆成可编排、可复核、可回退的任务链,而不是一次性把全文交给模型。
它适合用于验证:长文档分段策略、章节级抽取任务、结构化字段回填、低置信度片段进入人工复核、抽取结果回链到原文位置。
架构位置与边界
LongParser 应放在“文档理解层”,输入来自 SVN 只读采集后的原文和解析文本,输出只允许写入候选结构化结果、片段引用和复核任务。生产事实仍需经过人工确认或规则校验后进入结构化索引。
落地判断
它补充 RAGFlow 的“深度文档 RAG”视角,重点看任务编排和长上下文切分;不把它当企业文档管理系统,也不让模型抽取直接覆盖已确认字段。核心对象与数据模型
| 对象 | 作用 | 本项目映射 |
|---|---|---|
长文档任务Document Parse Job | 记录文档、版本、解析策略、运行状态和失败原因。 | parse_jobs |
章节片段Section Chunk | 按标题、页码、表格和语义边界切分后的处理单元。 | document_chunks |
抽取候选Extraction Candidate | 模型或规则生成的字段、摘要、实体和关系候选。 | field_candidates |
证据定位Evidence Anchor | 每个候选结果回链到页码、段落、表格行列或原始文本范围。 | evidence_spans |
复核任务Review Task | 低置信度、冲突或高风险字段进入人工复核队列。 | review_queue |
主流程与数据流
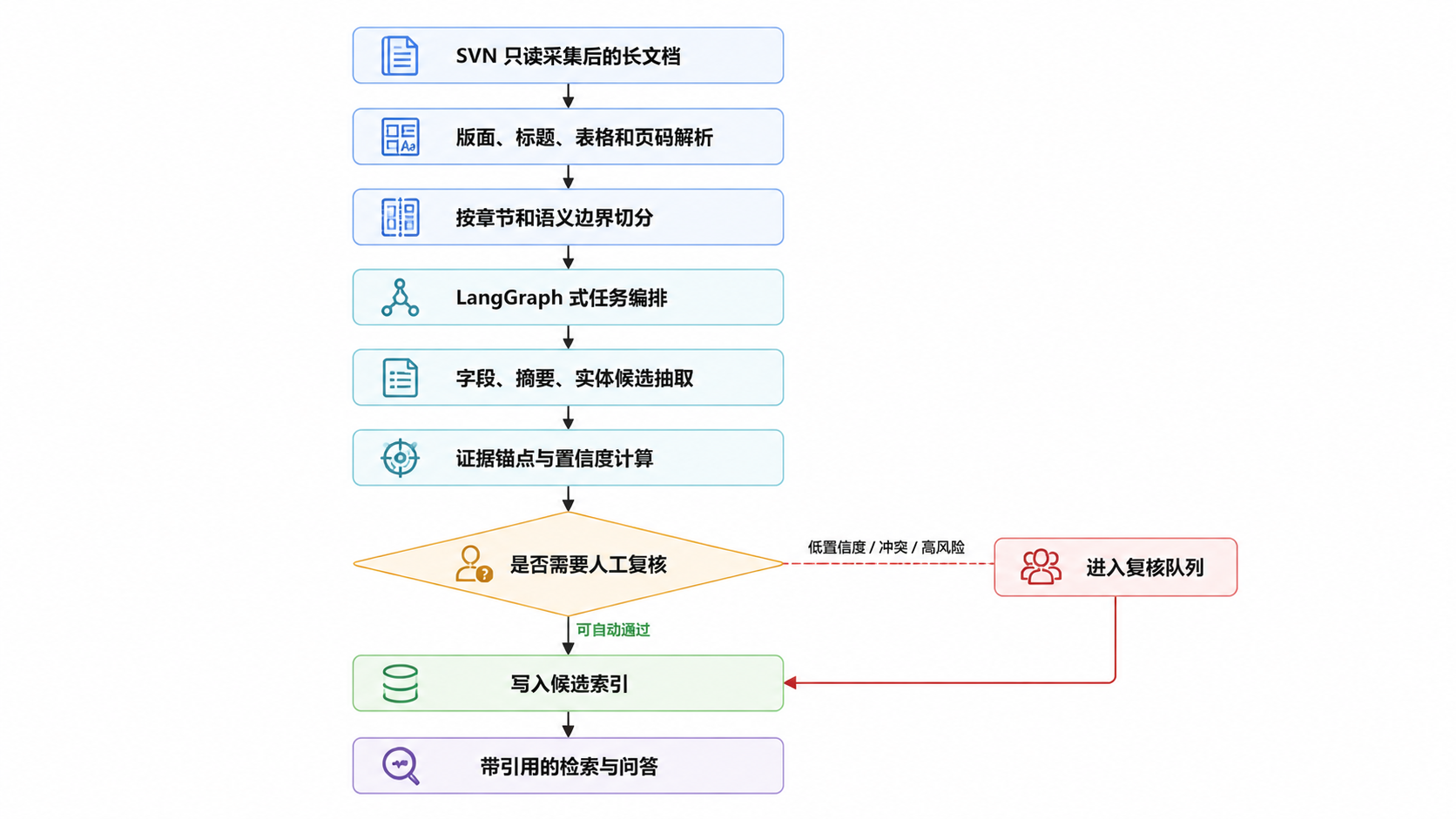
图 2.5.12 · LongParser 适合验证的长文档解析闭环。
关键实现机制
| 机制 | 拆解说明 |
|---|---|
| 任务图编排 | 把解析、切分、抽取、校验、复核拆成节点,便于失败重试和单节点替换。 |
| 长文档分层切分 | 先按结构边界切分,再按语义长度细分,减少跨章节混淆。 |
| 候选事实隔离 | 模型输出只能进入候选表,经过人工确认或规则校验后才成为生产事实。 |
| 证据先行 | 每个字段候选必须有原文锚点,不能只有模型生成文本。 |
映射到本项目
| 本项目设计点 | 落地说明 |
|---|---|
| 合同字段抽取试点 | 选择 30 份长合同,验证字段、金额、主体、期限、附件引用的抽取稳定性。 |
| 解析策略版本化 | 把切分规则、模型提示词和校验规则记录到解析任务版本里,便于回放。 |
| 复核队列 | 低置信度字段直接进入 Argilla 或本项目复核台,不自动写入事实库。 |
| RAGFlow 对照实验 | 同一批文档与 RAGFlow 结果对比,判断长文档任务图是否值得保留。 |
落地要点
- 对 30 份长合同和制度文件跑抽取,统计字段准确率、证据命中率和人工复核比例。
- 模拟解析失败、模型超时、表格跨页等异常,确认任务图可以局部重试。
- 每个候选字段都要保留 SVN 路径、版本、页码或文本范围。
- 与 RAGFlow 的片段质量和引用质量做 A/B 对照。