关键特性
关键特性
相关源文件
本章引用的主要源码文件:
README.mdargilla-server/src/argilla_server/api/schemas/v1/suggestions.pyargilla/README.mdargilla/docs/assets/images/getting_started/dataset_configurator.pngargilla/docs/assets/images/how_to_guides/custom_field/3d_object_viewer.pngargilla/docs/assets/images/how_to_guides/custom_field/images_in_two_columns.pngargilla/docs/assets/images/how_to_guides/custom_field/metadata_table.pngargilla/docs/community/adding_language.mdargilla/docs/getting_started/faq.mdargilla/docs/getting_started/how-to-configure-argilla-on-huggingface.mdargilla/docs/getting_started/how-to-deploy-argilla-with-docker.mdargilla/docs/getting_started/quickstart.mdargilla/docs/how_to_guides/annotate.mdargilla/docs/how_to_guides/custom_fields.mdargilla/docs/how_to_guides/dataset.mdargilla/docs/how_to_guides/distribution.mdargilla/docs/how_to_guides/import_export.mdargilla/docs/how_to_guides/index.mdargilla/docs/how_to_guides/query.mdargilla/docs/how_to_guides/record.mdargilla/docs/index.mdargilla/docs/reference/argilla/client.mdargilla/docs/reference/argilla/datasets/dataset_records.mdargilla/docs/reference/argilla/records/metadata.mdargilla/docs/reference/argilla/records/records.mdargilla/docs/reference/argilla/records/responses.mdargilla/docs/reference/argilla/records/suggestions.mdargilla/docs/reference/argilla/search.mdargilla/docs/reference/argilla/settings/fields.mdargilla/docs/tutorials/image_classification.ipynbargilla/docs/tutorials/image_preference.ipynbargilla/docs/tutorials/index.mdargilla/docs/tutorials/text_classification.ipynbargilla/docs/tutorials/token_classification.ipynbargilla/mkdocs.ymlargilla/src/argilla/_models/_dataset_progress.pyargilla/src/argilla/settings/_question.py
本文档概述了 Argilla 的主要功能。Argilla 是一个用于 AI 数据标注和模型改进的平台。它涵盖了核心特性,包括数据集管理、标注能力、搜索与过滤、AI 集成以及部署选项。如需了解高层级的架构总览,请参阅架构总览。
核心组件与数据模型
Argilla 的架构围绕几个关键组件构建,这些组件协同工作,提供了一个全面的数据标注平台。
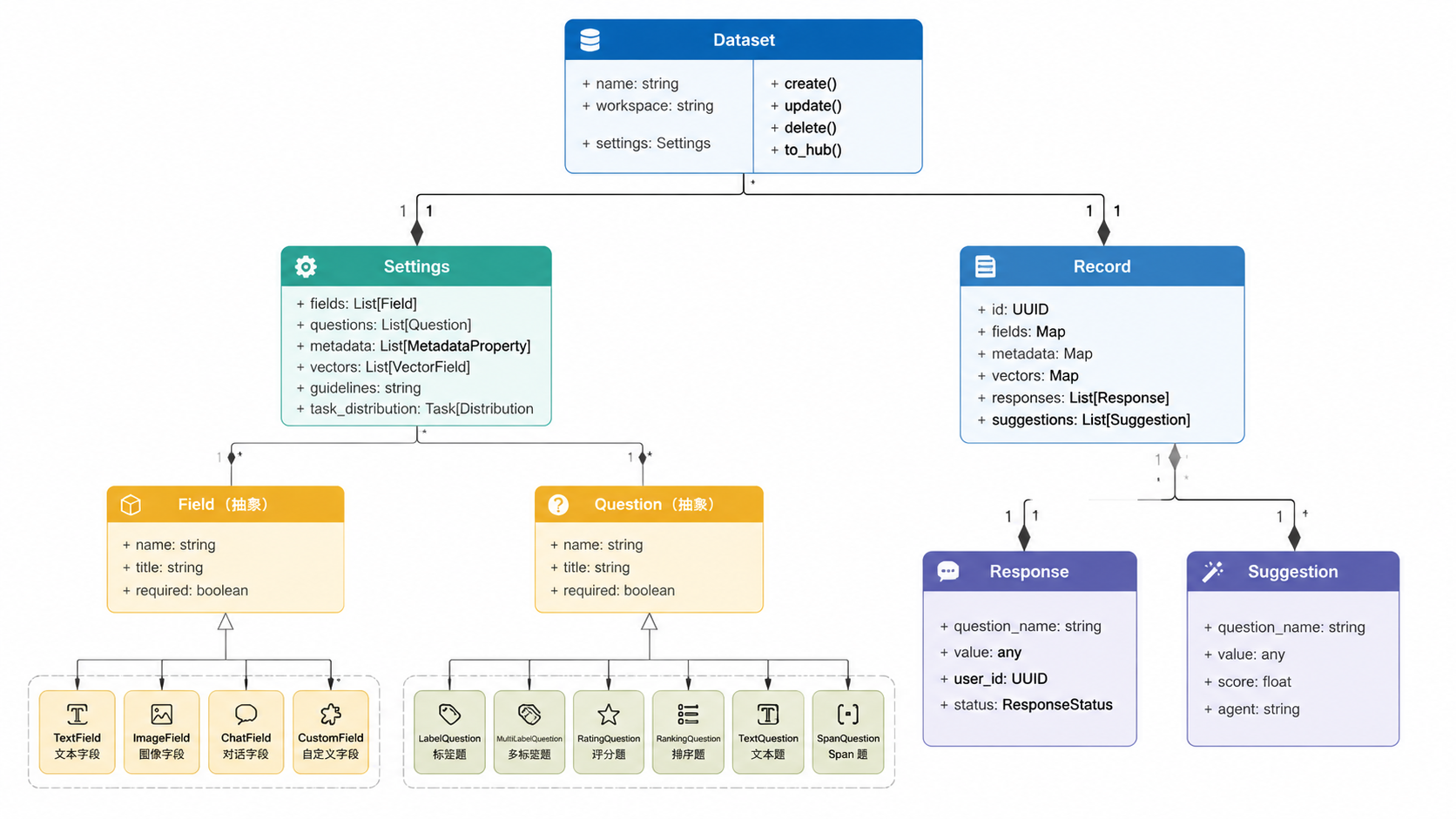
Argilla 的数据模型围绕 Dataset 对象展开,这些对象包含 Settings(定义数据集结构)和 Record 对象(包含实际数据)。记录可以包含 Responses(标注)和 Suggestions(模型预测)。
来源:argilla/docs/how_to_guides/dataset.md:1-626, argilla/docs/how_to_guides/record.md:1-613, argilla/src/argilla/settings/_question.py:1-128
数据集管理
Argilla 提供了全面的数据集管理能力:
创建与配置
用户可以创建具有自定义设置的数据集,包括字段、问题、元数据、向量和指南:
settings = rg.Settings(
guidelines="将评论分类为正面或负面。",
fields=[
rg.TextField(name="review", title="评论文本"),
],
questions=[
rg.LabelQuestion(
name="sentiment_label",
title="这篇文章属于哪个类别?",
labels=["正面", "负面"],
)
],
)
dataset = rg.Dataset(
name="my_dataset",
settings=settings,
).create()来源:argilla/docs/how_to_guides/dataset.md:51-94, argilla/docs/tutorials/text_classification.ipynb:150-172
字段类型
Argilla 支持多种字段类型来展示不同类型的数据:
| 字段类型 | 描述 | 用例 |
|---|---|---|
| TextField | 纯文本或 Markdown | 文本分类 |
| ImageField | 远程 URL、本地路径或 PIL 图像 | 图像分类 |
| ChatField | 带有角色和内容的结构化聊天 | 对话式 AI |
| CustomField | 自定义 HTML/CSS/JS 模板 | 复杂可视化 |
来源:argilla/docs/how_to_guides/dataset.md:146-211, argilla/docs/reference/argilla/settings/fields.md:1-50
问题类型
Argilla 提供了多种问题类型,适用于不同的标注任务:
| 问题类型 | 描述 | 用例 |
|---|---|---|
| LabelQuestion | 单选标签 | 文本分类 |
| MultiLabelQuestion | 多选标签 | 主题标记 |
| RankingQuestion | 按偏好排序选项 | 偏好学习 |
| RatingQuestion | 按等级进行数值评分 | 质量评估 |
| SpanQuestion | 使用标签选择文本片段 | 命名实体识别 |
| TextQuestion | 自由文本回复 | 反馈收集 |
来源:argilla/docs/how_to_guides/dataset.md:212-327, argilla/docs/reference/argilla/settings/fields.md:1-50
元数据与向量
元数据属性支持过滤和排序,而向量则为语义相似性搜索提供支持:
# 添加元数据属性
rg.TermsMetadataProperty(
name="category",
options=["新闻", "博客", "社交"],
title="内容类别",
)
# 添加向量字段
rg.VectorField(
name="embeddings",
title="文本嵌入向量",
dimensions=768
)来源:argilla/docs/how_to_guides/dataset.md:329-391, argilla/docs/how_to_guides/record.md:267-302
标注工作流
Argilla 提供了一个简化的标注工作流,包含不同的记录状态和队列:
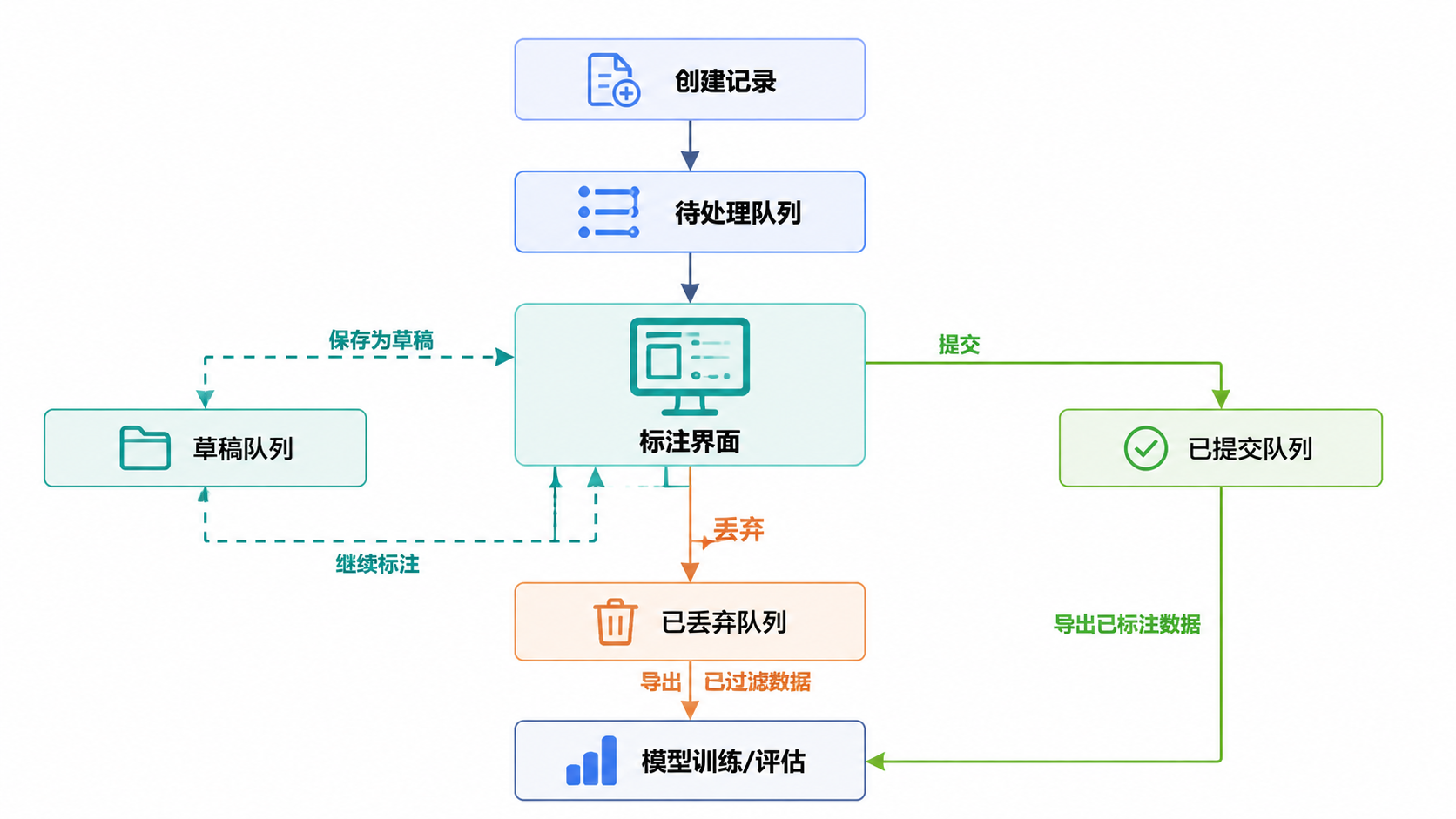
标注过程遵循一个系统化的流程,记录会根据用户的操作在不同状态间流转:
- 待处理:等待标注的记录
- 草稿:部分标注的记录
- 已提交:完成标注的记录
- 已丢弃:被拒绝的记录
每种状态都有助于跟踪进度,并高效地组织标注工作流。
来源:argilla/docs/how_to_guides/annotate.md:1-180
记录管理
添加记录
可以从多种来源向数据集添加记录:
# 从 Record 对象添加
records = [
rg.Record(fields={"text": "你好,世界"}),
rg.Record(fields={"text": "另一个例子"})
]
dataset.records.log(records)
# 从 Hugging Face 数据集添加
from datasets import load_dataset
hf_dataset = load_dataset("imdb", split="train[:100]")
dataset.records.log(hf_dataset, mapping={"text": "review"})来源:argilla/docs/how_to_guides/record.md:38-155, argilla/docs/reference/argilla/records/records.md:1-69
添加模型建议
Argilla 允许将模型预测作为建议添加,以加速标注过程:
# 直接添加建议
record = rg.Record(
fields={"text": "你好,世界"},
suggestions=[
rg.Suggestion("label", "正面", score=0.9, agent="model_name")
]
)
# 使用新建议更新现有记录
updated_data = [
{
"id": record_id,
"label": prediction,
"score": confidence,
}
for record_id, prediction, confidence in predictions
]
dataset.records.log(updated_data)建议会在用户界面中以闪烁图标(✨)显示,标注人员可以接受或修正这些建议。
来源:argilla/docs/tutorials/text_classification.ipynb:252-370, argilla/docs/reference/argilla/records/suggestions.md:1-155
搜索与过滤
Argilla 提供了强大的搜索和过滤能力:
关键词搜索
query = rg.Query(query="重要术语")
results = dataset.records(query=query)支持高级查询语法(类似于 Elasticsearch),用于复杂搜索。
按属性过滤
# 按元数据过滤
metadata_filter = rg.Filter(("category", "==", "新闻"))
# 按建议过滤
suggestion_filter = rg.Filter(("label.suggestion", "==", "正面"))
# 按响应状态过滤
status_filter = rg.Filter(("response.status", "==", "submitted"))
# 组合过滤条件
combined_filter = rg.Query(
filter=rg.Filter([
("category", "==", "新闻"),
("label.suggestion", "==", "正面")
])
)语义搜索
如果已向记录添加了向量,则可以进行语义相似性搜索:
similar = rg.Similar(
name="embeddings",
value=[0.1, 0.2, ..., 0.7], # 768 维向量
)
similar_records = dataset.records(query=rg.Query(similar=similar))来源:argilla/docs/how_to_guides/query.md:1-100, argilla/docs/how_to_guides/annotate.md:130-180, argilla/docs/reference/argilla/search.md:1-50
导入与导出
Argilla 提供了灵活的导入和导出数据集选项:
Hugging Face Hub 集成
# 将数据集导出到 Hugging Face Hub
dataset.to_hub(repo_id="username/dataset-name")
# 从 Hugging Face Hub 导入数据集
imported_dataset = rg.Dataset.from_hub(
repo_id="username/dataset-name",
name="local_name"
)导出为 Python 格式
# 导出为 Hugging Face Dataset
hf_dataset = dataset.records.to_datasets()
# 导出为字典
records_dict = dataset.records.to_dict()
# 导出为列表
records_list = dataset.records.to_list(flatten=True)来源:argilla/docs/how_to_guides/import_export.md:1-164
任务分发
Argilla 通过任务分发支持协作式标注:
# 配置每条记录所需的最少响应数
settings = rg.Settings(
# ... 其他设置
distribution=rg.TaskDistribution(min_submitted=2),
)此设置确保每条记录至少获得指定数量的标注,这对于创建共识或衡量标注者间一致性非常有用。
来源:argilla/docs/how_to_guides/dataset.md:412-424, argilla/docs/how_to_guides/distribution.md:1-20
部署选项
Argilla 可以通过多种方式进行部署:
Hugging Face Spaces(推荐)
# 使用 Python SDK 部署
import argilla as rg
client = rg.Argilla.deploy_on_spaces(api_key="your_api_key")或者使用 Hugging Face Hub 界面中的部署按钮。
Docker 部署
# 下载 docker-compose.yaml
wget -O docker-compose.yaml https://raw.githubusercontent.com/argilla-io/argilla/main/examples/deployments/docker/docker-compose.yaml
# 启动服务器
docker compose up -d来源:argilla/docs/getting_started/quickstart.md:1-173, argilla/docs/getting_started/how-to-deploy-argilla-with-docker.md:1-41, argilla/docs/reference/argilla/client.md:1-63
自定义
自定义字段
Argilla 支持使用自定义的 HTML/CSS/JavaScript 模板来实现复杂的可视化:
template = """
<style>
#container { display: flex; gap: 10px; }
.column { flex: 1; }
</style>
<div id="container">
<div class="column">
<h3>原始图像</h3>
<img src="{{record.fields.image.original}}" />
</div>
<div class="column">
<h3>修订版本</h3>
<img src="{{record.fields.image.revision}}" />
</div>
</div>
"""
custom_field = rg.CustomField(
name="image_comparison",
template=template
)Markdown 支持
文本字段可以渲染 Markdown 以显示富文本内容:
rg.TextField(
name="instructions",
title="任务说明",
use_markdown=True
)来源:argilla/docs/how_to_guides/custom_fields.md:1-339, argilla/docs/how_to_guides/use_markdown_to_format_rich_content.md:1
端到端工作流
Argilla 支持针对各种 AI 任务的完整标注工作流:
- 创建数据集,包含适当的字段和问题
- 添加记录,来自多种来源
- 添加模型建议,以加速标注
- 标注记录,通过用户界面
- 导出已标注数据,用于模型训练
- 微调模型,使用已标注的数据
- 评估模型性能
许多教程针对特定用例(如文本分类、Token 分类、图像分类等)演示了这些工作流。
来源:argilla/docs/tutorials/text_classification.ipynb:1-547, argilla/docs/tutorials/token_classification.ipynb:1-547, argilla/docs/tutorials/index.md:1-47
社区与生态系统
Argilla 是一个开源、社区驱动的项目,拥有不断增长的生态系统集成:
- Hugging Face Hub 集成,用于数据集和模型
- 大语言模型(LLM)框架集成,用于反馈收集和微调
- 社区贡献,贡献数据集和模型
- 定期社区聚会,用于知识分享
来源:README.md:35-79, argilla/docs/index.md:51-86