Argilla SDK
Argilla SDK
相关源文件
本章引用的主要源码文件:
argilla-frontend/CHANGELOG.mdargilla-frontend/components/features/annotation/container/questions/form/span/EntityLabelSelection.component.vueargilla-frontend/components/features/annotation/settings/Validation.vueargilla-frontend/components/features/dataset-creation/configuration/DatasetConfigurationForm.vueargilla-frontend/components/features/dataset-creation/configuration/questions/DatasetConfigurationFieldSelector.vueargilla-frontend/components/features/dataset-creation/configuration/questions/DatasetConfigurationLabels.vueargilla-frontend/components/features/dataset-creation/configuration/questions/DatasetConfigurationQuestion.vueargilla-frontend/components/features/dataset-creation/configuration/questions/DatasetConfigurationRating.vueargilla-frontend/components/features/dataset-creation/configuration/questions/DatasetConfigurationSpan.vueargilla-frontend/package.jsonargilla-frontend/translation/de.jsargilla-frontend/translation/en.jsargilla-frontend/translation/es.jsargilla-frontend/v1/domain/entities/hub/DatasetCreation.test.tsargilla-frontend/v1/domain/entities/hub/QuestionCreation.tsargilla-frontend/v1/domain/entities/hub/Subset.tsargilla-server/CHANGELOG.mdargilla-server/README.mdargilla-server/src/argilla_server/_version.pyargilla-server/src/argilla_server/api/handlers/v1/users.pyargilla-server/src/argilla_server/api/policies/v1/user_policy.pyargilla-server/src/argilla_server/api/schemas/v1/users.pyargilla-server/src/argilla_server/api/schemas/v1/workspaces.pyargilla-server/src/argilla_server/contexts/accounts.pyargilla-server/tests/unit/api/handlers/v1/users/test_create_user.pyargilla-server/tests/unit/api/handlers/v1/users/test_update_user.pyargilla-server/tests/unit/api/handlers/v1/workspaces/test_create_workspace.pyargilla-v1/src/argilla_v1/_version.pyargilla/CHANGELOG.mdargilla/docs/how_to_guides/migrate_from_legacy_datasets.mdargilla/pdm.lockargilla/pyproject.tomlargilla/src/argilla/__init__.pyargilla/src/argilla/_api/_workspaces.pyargilla/src/argilla/_models/_record/_record.pyargilla/src/argilla/_version.pyargilla/src/argilla/records/_dataset_records.pyargilla/src/argilla/records/_io/_datasets.pyargilla/src/argilla/records/_io/_generic.pyargilla/src/argilla/records/_io/_json.pyargilla/src/argilla/records/_mapping/_mapper.pyargilla/src/argilla/records/_mapping/_routes.pyargilla/src/argilla/records/_resource.pyargilla/src/argilla/records/_search.pyargilla/src/argilla/users/_resource.pyargilla/src/argilla/v1/__init__.pyargilla/src/argilla/workspaces/_resource.pyargilla/tests/integration/test_export_dataset.pyargilla/tests/integration/test_export_records.pyargilla/tests/integration/test_list_records.pyargilla/tests/integration/test_manage_users.pyargilla/tests/integration/test_manage_workspaces.pyargilla/tests/integration/test_query_records.pyargilla/tests/integration/test_search_records.pyargilla/tests/unit/export/test_record_export_import_compatibillity.pyargilla/tests/unit/test_io/test_generic.pyargilla/tests/unit/test_io/test_hf_datasets.pyargilla/tests/unit/test_record_fields.pyargilla/tests/unit/test_record_ingestion.pyargilla/tests/unit/test_resources/test_records.py
Argilla SDK 是一个 Python 客户端库,提供了与 Argilla(一个用于数据标注和 AI 模型改进的协作平台)进行编程交互的接口。该库允许用户创建、管理和标注数据集,并将 Argilla 集成到机器学习工作流中。
有关 Argilla 服务器的信息,请参阅 Argilla Server。有关前端界面的详细信息,请参阅 Argilla Frontend。
概述
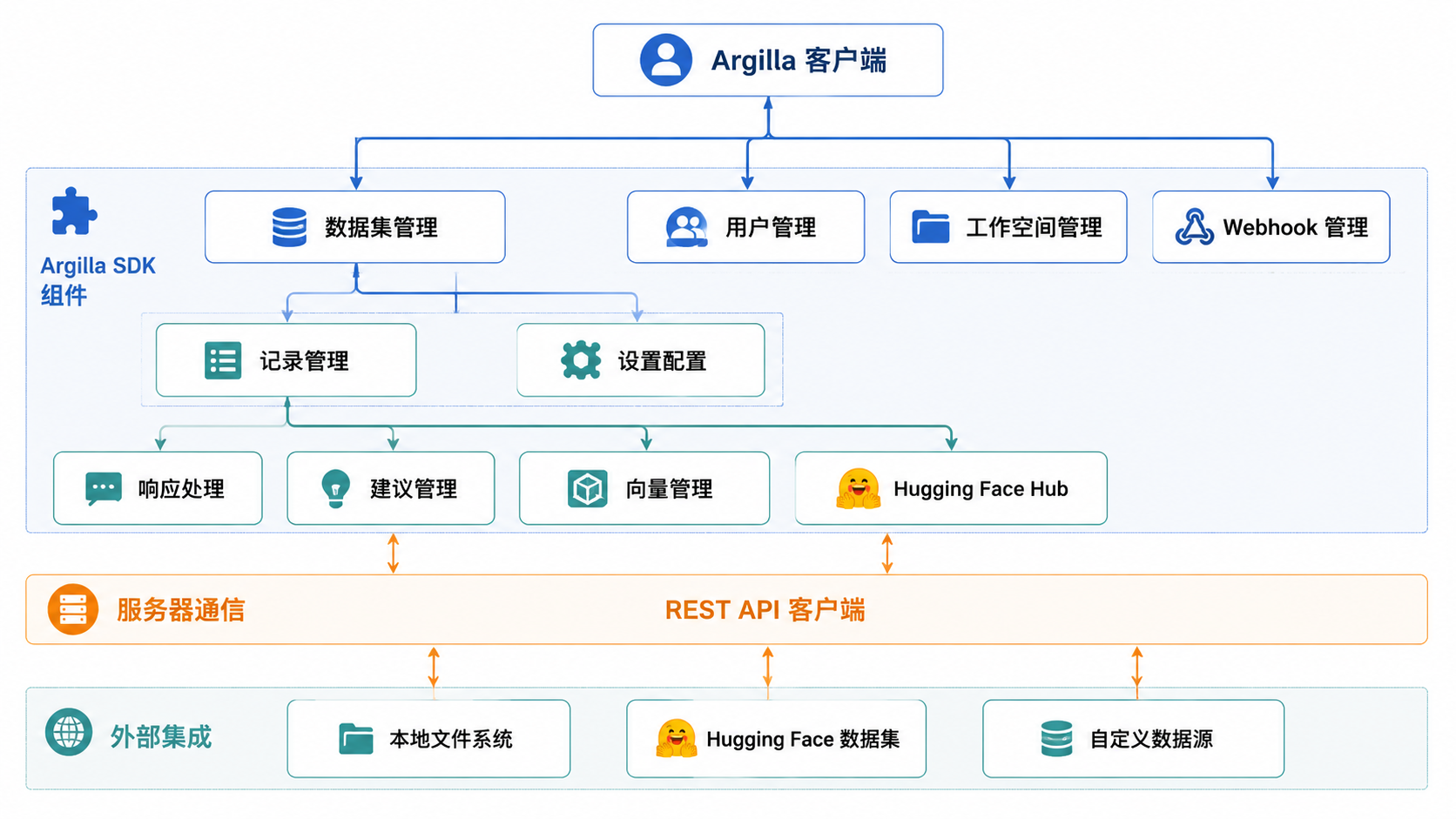
来源: argilla/src/argilla/__init__.py argilla/pyproject.toml argilla/CHANGELOG.md
安装
您可以使用 pip 安装 Argilla SDK:
pip install argilla该 SDK 需要 Python 3.9 或更高版本,并依赖 httpx、pydantic、huggingface_hub、tqdm、rich 和 datasets 等库。
来源: argilla/pyproject.toml
核心组件
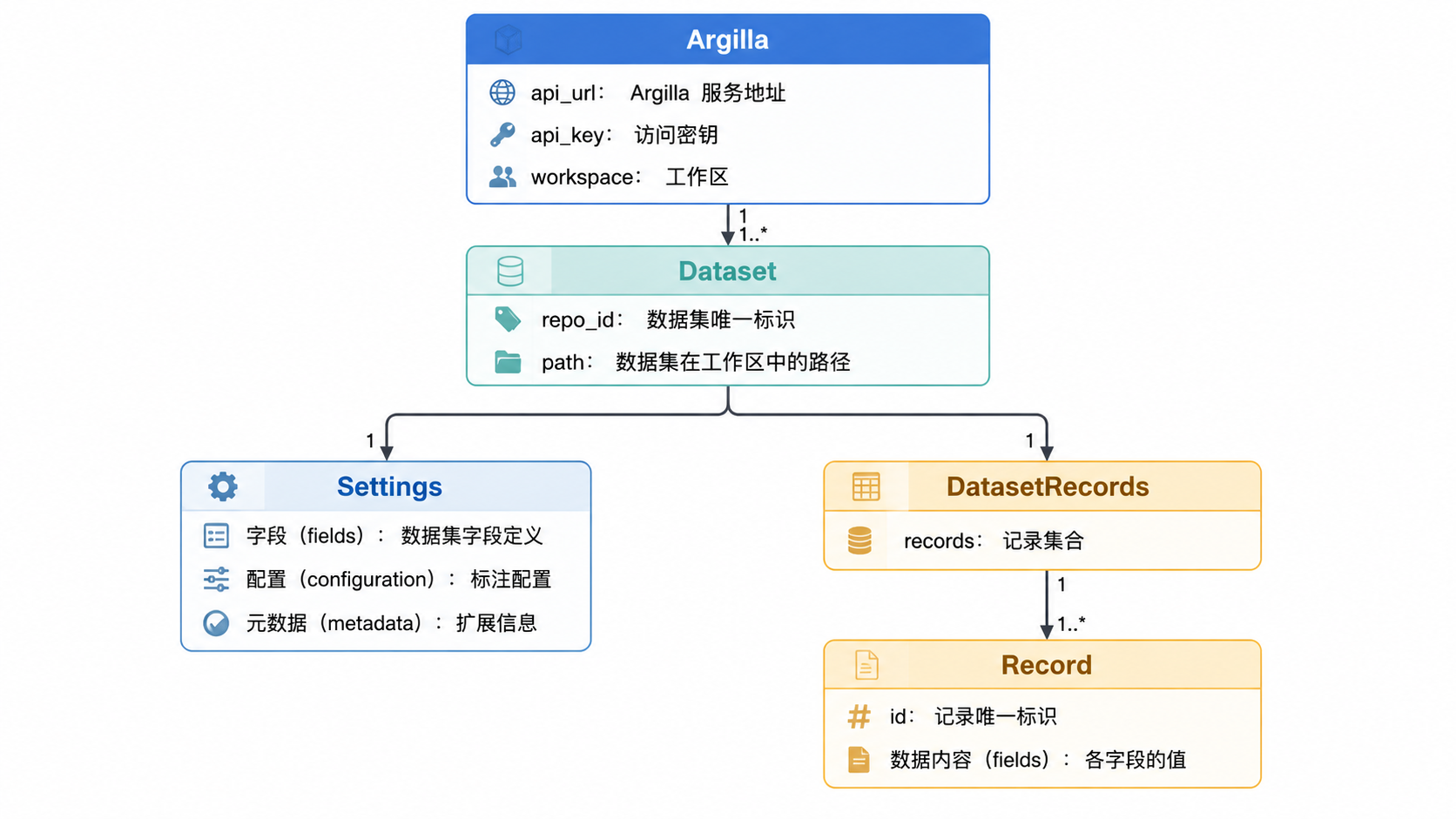
来源: argilla/src/argilla/__init__.py argilla/src/argilla/records/_resource.py argilla/src/argilla/records/_dataset_records.py
Argilla 客户端
Argilla 客户端是与 Argilla 服务器交互的主要入口点。它提供了访问数据集、工作空间和用户的方法。
import argilla as rg
# 初始化客户端 - 如果默认服务器可用,会自动连接
client = rg.Argilla(
api_url="https://your-argilla-server.com",
api_key="your-api-key",
workspace="your-workspace"
)
# 访问当前用户
user = client.me
# 列出可用数据集
datasets = client.datasets()客户端会自动处理认证并维护与服务器的连接。
来源: argilla/src/argilla/__init__.py
数据集与设置
数据集是 Argilla 中数据的主要容器。每个数据集都有名称、工作空间和定义其结构的设置。
Settings 对象定义了以下内容:
- 字段(Fields):显示哪些数据(TextField、ImageField、ChatField、CustomField)
- 问题(Questions):标注什么内容(LabelQuestion、MultiLabelQuestion、RatingQuestion 等)
- 元数据属性(Metadata Properties):关于记录的附加信息
- 向量设置(Vector Settings):嵌入向量的配置
- 指南(Guidelines):给标注者的说明
- 任务分配(Task Distribution):记录如何分配给标注者
# 创建数据集设置
settings = rg.Settings(
fields=[
rg.TextField(name="text", required=True),
rg.ImageField(name="image", required=False),
],
questions=[
rg.LabelQuestion(name="sentiment", labels=["positive", "negative", "neutral"]),
rg.RatingQuestion(name="relevance", values=[1, 2, 3, 4, 5]),
],
metadata=[
rg.TermsMetadataProperty(name="source"),
],
guidelines="请将文本的情感分类为正面、负面或中性。"
)
# 创建并发布数据集
dataset = rg.Dataset(name="sentiment-analysis", settings=settings)
dataset.create()来源: argilla/src/argilla/__init__.py argilla/CHANGELOG.md argilla/tests/integration/test_export_dataset.py
记录
记录是数据集中的单个数据样本。每条记录包含字段、元数据、向量、响应和建议。
# 向数据集写入记录
dataset.records.log([
{
"text": "我超爱这个产品!",
"image": "https://example.com/image.jpg",
"sentiment": "positive", # 这将作为建议添加
"source": "web", # 这将作为元数据添加
},
{
"text": "这太糟糕了。",
"image": "https://example.com/image2.jpg",
"sentiment": "negative",
"source": "reviews",
}
])
# 查询记录
for record in dataset.records(query="terrible", with_suggestions=True):
print(record.id, record.fields["text"], record.suggestions["sentiment"].value)SDK 会根据数据集的设置,自动将扁平字典数据映射到相应的记录字段、元数据和建议。
来源: argilla/src/argilla/records/_resource.py argilla/src/argilla/records/_dataset_records.py argilla/tests/unit/test_resources/test_records.py argilla/tests/unit/test_record_ingestion.py
响应与建议
响应代表用户提供的标注,而建议是预先填充的答案,通常来自模型。
# 向记录添加响应
record.responses.append(
rg.Response(
question_name="sentiment",
value="positive",
user_id=user.id
)
)
# 向记录添加建议
record.suggestions.append(
rg.Suggestion(
question_name="sentiment",
value="positive",
score=0.95,
agent="model-v1"
)
)在写入记录时,SDK 会自动将字典值映射到问题字段的建议。
来源: argilla/src/argilla/records/_resource.py argilla/tests/unit/test_resources/test_records.py
向量
向量是记录的嵌入向量或数值表示,用于相似性搜索和其他操作。
# 定义向量设置
settings = rg.Settings(
fields=[rg.TextField(name="text")],
questions=[rg.LabelQuestion(name="label", labels=["positive", "negative"])],
vectors=[rg.VectorField(name="embeddings", dimensions=384)]
)
# 写入包含向量数据的记录
dataset.records.log([
{
"text": "你好世界",
"label": "positive",
"embeddings": [0.1, 0.2, 0.3, ..., 0.384] # 384 维向量
}
])
# 查找相似记录
similar_records = dataset.records.find_similar_records(
record_id="record-id",
vector_name="embeddings",
limit=10
)来源: argilla/CHANGELOG.md argilla/tests/integration/test_export_records.py
常见工作流
创建数据集
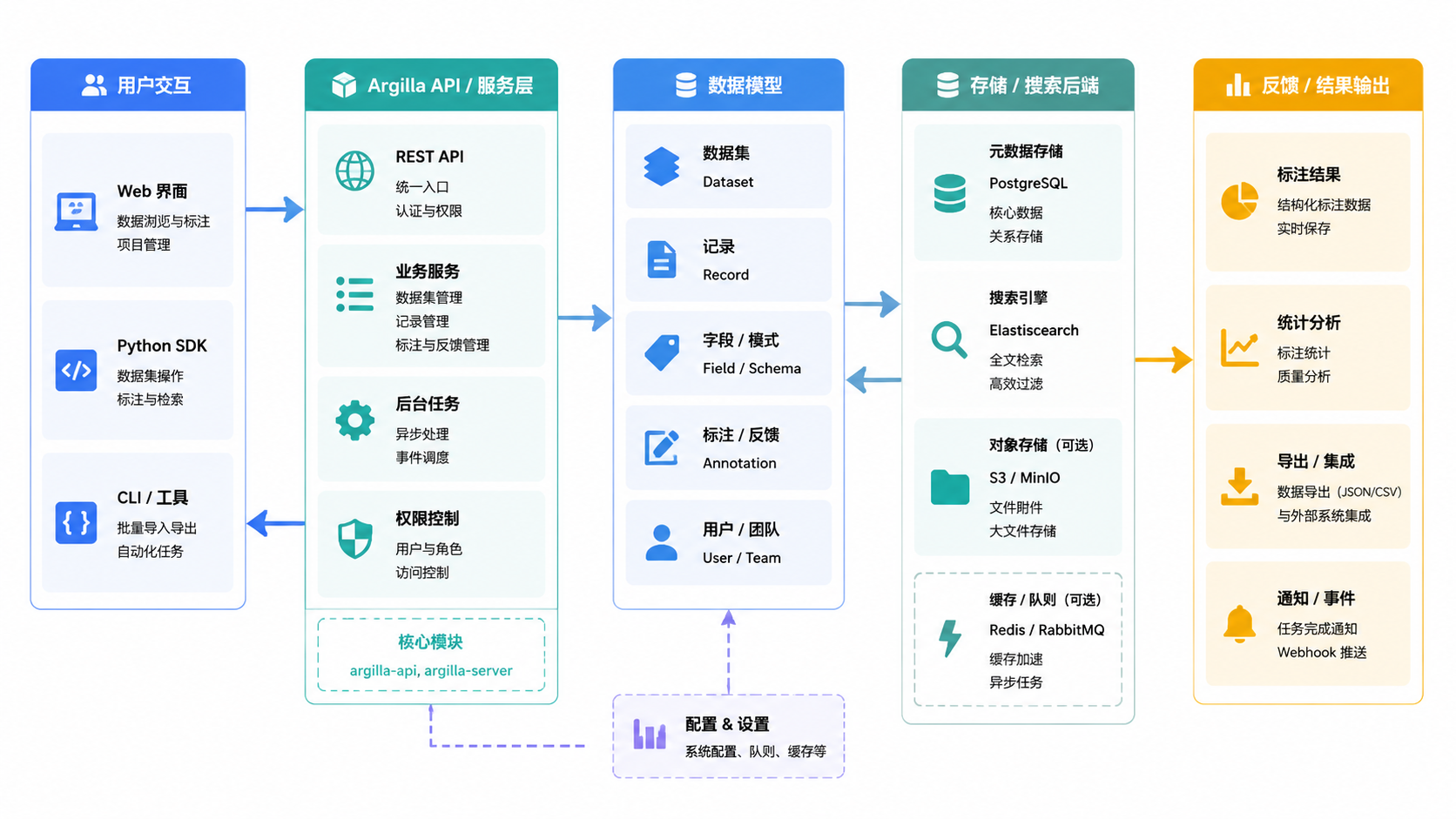
来源: argilla/src/argilla/records/_dataset_records.py argilla/tests/integration/test_export_dataset.py
从 Hugging Face Hub 导入
Argilla 与 Hugging Face Hub 紧密集成,允许您从仓库创建数据集:
# 从 Hugging Face Hub 导入数据集
dataset = rg.Dataset.from_hub(
repo_id="stanfordnlp/imdb",
name="imdb-sentiment",
settings="auto", # 根据数据集结构自动生成设置
with_records=True # 同时导入记录
)您也可以直接导入 Hugging Face 数据集:
from datasets import load_dataset
hf_dataset = load_dataset("stanfordnlp/imdb")
# 将数据集映射到 Argilla 设置
settings = rg.Settings(
fields=[rg.TextField(name="text")],
questions=[rg.LabelQuestion(name="sentiment", labels=["positive", "negative"])]
)
dataset = rg.Dataset(name="imdb", settings=settings)
dataset.create()
# 从 Hugging Face 数据集写入记录
dataset.records.log(hf_dataset["train"])来源: argilla/tests/integration/test_export_dataset.py argilla/src/argilla/records/_io/_datasets.py
搜索和过滤记录
SDK 提供了强大的记录搜索功能:
# 简单文本搜索
results = dataset.records(query="important keyword")
# 使用 Query 对象进行高级过滤
from argilla.records import Query
query = Query(
query="important",
filter={"metadata.source": "web"}
)
results = dataset.records(query=query)
# 向量相似性搜索
similar = dataset.records.find_similar_records(
record_id="record-id",
vector_name="embeddings"
)来源: argilla/src/argilla/records/_dataset_records.py argilla/tests/integration/test_list_records.py
导出数据
数据可以导出为多种格式:
# 导出为字典
data_dict = dataset.records().to_dict()
# 导出为列表
data_list = dataset.records().to_list()
# 导出为 JSON 文件
json_path = dataset.records().to_json("/path/to/output.json")
# 导出为 Hugging Face 数据集
hf_dataset = dataset.records().to_datasets()
# 将数据集导出到 Hugging Face Hub
dataset.to_hub(
repo_id="username/dataset-name",
with_records=True,
private=True,
token="your-huggingface-token"
)
# 将数据集导出到磁盘
dataset.to_disk(
path="/path/to/output",
with_records=True
)来源: argilla/tests/integration/test_export_dataset.py argilla/tests/integration/test_export_records.py argilla/src/argilla/records/_dataset_records.py
用户与工作空间管理
SDK 提供了管理用户和工作空间的函数:
# 列出所有用户
users = client.users()
# 创建新用户
new_user = rg.User(
username="new_user",
password="password123",
first_name="New",
last_name="User",
role="annotator"
)
client.users.add(new_user)
# 列出所有工作空间
workspaces = client.workspaces()
# 创建新工作空间
new_workspace = rg.Workspace(name="new-workspace")
new_workspace.create()
# 将用户添加到工作空间
new_user.add_to_workspace(new_workspace)来源: argilla/tests/integration/test_manage_users.py argilla-server/src/argilla_server/contexts/accounts.py
高级功能
Webhook
Webhook 允许您在特定事件发生时接收通知:
# 创建 Webhook
webhook = rg.Webhook(
url="https://your-endpoint.com/webhook",
events=["response.created", "dataset.published"],
name="My Webhook"
)
client.webhooks.add(webhook)来源: argilla/src/argilla/__init__.py argilla/CHANGELOG.md
批量操作
SDK 支持批量操作以实现高效处理:
# 批量写入记录
dataset.records.log(
records=large_record_list,
batch_size=256 # 控制批次大小以获得更好性能
)
# 批量更新记录
dataset.records.log(
records=records_with_updates, # 相同 ID 的记录将被更新
batch_size=256
)
# 批量删除记录
dataset.records.delete(
records=records_to_delete,
batch_size=64
)来源: argilla/src/argilla/records/_dataset_records.py argilla/tests/unit/test_record_ingestion.py
错误处理
SDK 为记录入库提供了可配置的错误处理:
# 不同的错误处理选项
dataset.records.log(
records=records_list,
on_error=rg.RecordErrorHandling.RAISE # 遇到第一个错误时停止
)
dataset.records.log(
records=records_list,
on_error=rg.RecordErrorHandling.WARN # 记录警告但继续执行
)
dataset.records.log(
records=records_list,
on_error=rg.RecordErrorHandling.IGNORE # 静默跳过错误
)来源: argilla/src/argilla/records/_dataset_records.py argilla/tests/unit/test_record_ingestion.py
从旧版数据集迁移
对于从 Argilla v1.x 迁移的用户,SDK 提供了迁移工具:
# 连接到旧服务器
import argilla.v1 as rg_v1
rg_v1.init(api_url="old-server", api_key="old-key")
# 从旧服务器获取数据
old_dataset = rg_v1.load("old-dataset-name", "workspace")
old_settings = rg_v1.load_dataset_settings("old-dataset-name", "workspace")
old_records = old_dataset.to_datasets()
# 在 v2 中创建新数据集
import argilla as rg
new_settings = rg.Settings(
fields=[rg.TextField(name="text")],
questions=[rg.LabelQuestion(name="label", labels=old_settings.label_schema)]
)
new_dataset = rg.Dataset(name="new-dataset", settings=new_settings)
new_dataset.create()
# 导入旧记录
new_dataset.records.log(old_records)来源: argilla/docs/how_to_guides/migrate_from_legacy_datasets.md
与 Hugging Face 集成
Argilla 与 Hugging Face 有原生集成,支持:
- 从 Hugging Face Hub 导入数据集
- 将数据集导出到 Hugging Face Hub
- 在 Hugging Face Spaces 上部署 Argilla
# 在 Hugging Face Spaces 上部署
client.deploy_on_spaces()
# 从 Hub 导入数据集
dataset = rg.Dataset.from_hub(
repo_id="username/dataset-name",
name="local-name",
token="your-huggingface-token"
)
# 将数据集导出到 Hub
dataset.to_hub(
repo_id="username/dataset-name",
token="your-huggingface-token"
)来源: argilla/CHANGELOG.md argilla/tests/integration/test_export_dataset.py
总结
Argilla SDK 提供了一套全面的工具,用于:
- 创建和管理具有可自定义设置的数据集
- 高效写入和操作记录
- 与流行的机器学习工具和平台集成
- 管理用户和工作空间
- 以多种格式导入和导出数据
- 搜索和过滤记录,包括向量相似性搜索
- 接收事件的 Webhook 通知
该 SDK 构成了 Argilla 平台编程接口的基础,使用户能够将数据标注集成到他们的机器学习工作流中。