1.1 系统总览
把 SVN 事实源、文档解析、结构化索引、检索、人审反馈、应用编排和 智能体研究 拆成可独立替换的能力层,避免"找一个平台全包"的依赖陷阱。
相关来源文件
docs/00-main-report.md· 第 1–5 节,PDF 解析、检索、数据管理三档架构。docs/03-baseline-requirements.md· 一期边界与"做什么 / 不做什么"清单。docs/05-community-discussion-brief.md· 当前倾向架构与待挑战判断。docs/11-reference-platforms-agentic-knowledge-base.md· 第 2 节总体参考架构。
本页范围
本页面回答:
- 系统应当被切成哪些能力层,每层在一期、二期、三期的角色是什么。
- 为什么 SVN 不被替换,而是被"上面一层"包住。
- 各层之间的事实流、权限流和反馈流如何走。
本页面不讨论:标签算法(见 3)、入库表结构(见 4)、平台选型对比(见 2)。
分层参考架构
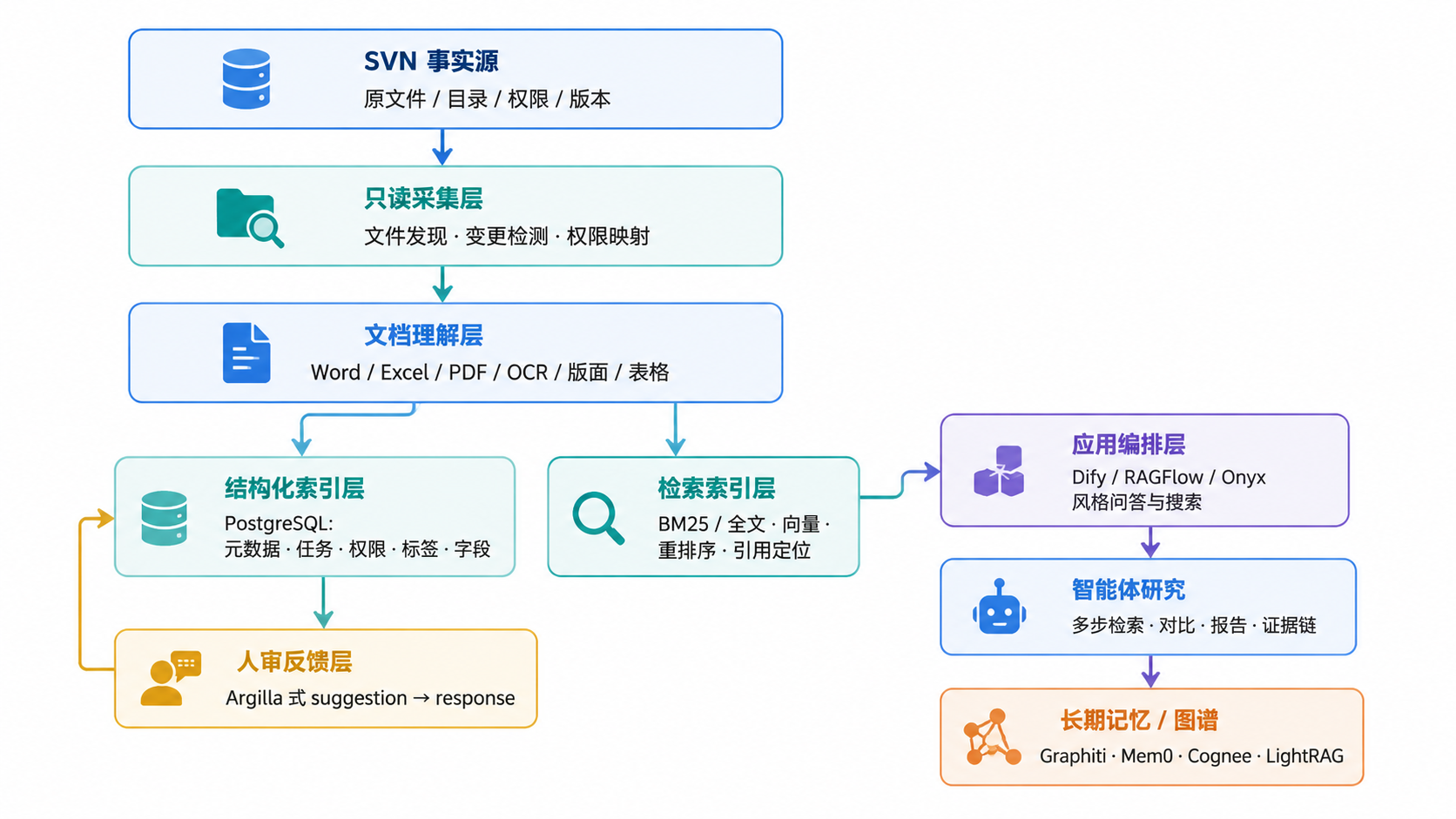
图 1.1 · 分层参考架构。事实流自上而下,反馈流自下而上回到结构化索引层。
每一层的角色
| 层 | 解决什么问题 | 一期 | 二期 | 三期 |
|---|---|---|---|---|
| SVN 事实源 | 文件、版本、authz 仍是企业事实 | 保留只读 | 保留只读 | 保留只读 |
| 只读采集 | 把 SVN 的文件、变更、权限拉到本地索引 | 必做 | 增量稳定化 | 多源 连接器 |
| 文档理解 | Word / Excel / 数字 PDF 优先;OCR 补盖章件 | 必做 | 新增表格 / 版面 | 多模态 验证 |
| 结构化索引 | 元数据、任务、权限、标签、字段 | 必做 | 稳态扩展 | 图谱节点 |
| 检索索引 | BM25 + 全文 · 标签过滤 · 引用定位 | BM25 + 全文 | + 向量 + 重排 | + 图检索 |
| 人审反馈 | AI 给建议 · 人确认才入库 | 简化审核 界面 | Argilla 闭环 | 主动学习 |
| 应用编排 | 问答、流程、模型编排 | 不做 | Dify 验证 | 多智能体 |
| 智能体研究 | 多步检索 · 报告 · 证据链 | 不做 | 不做 | 必做 |
| 长期记忆 / 图谱 | 项目 / 政策 / 客户的关系与时序记忆 | 不做 | 验证 | 必做 |
来源
docs/11-reference-platforms-agentic-knowledge-base.md §2、§11;docs/03-baseline-requirements.md §3。为什么不替换 SVN
调研期间反复出现的一个诱惑是"直接迁移到 Paperless-ngx 或 Mayan EDMS,让它们做事实源"。基线明确否决了这一选择,原因有三:
- 权限边界:企业 SVN authz 已经是事实边界,迁移会引入两套权限体系,难以审计。
- 使用习惯:业务人员把 SVN 当文件柜,目录、版本、命名都已沉淀,迁移阻力极高。
- 变更成本:原始文件搬离 SVN 的同时需要重写 Word 留档与盖章 PDF 的对应关系,得不偿失。
结论:把 EDMS / 检索增强生成工具当作设计模式参考而不是事实源容器,企业 SVN 仍保留为唯一的真实文件位置。
来源
docs/11-reference-platforms-agentic-knowledge-base.md §1、§3.2;docs/03-baseline-requirements.md §1、§4.2。三条数据流
事实流:原文 → 索引 → 检索结果
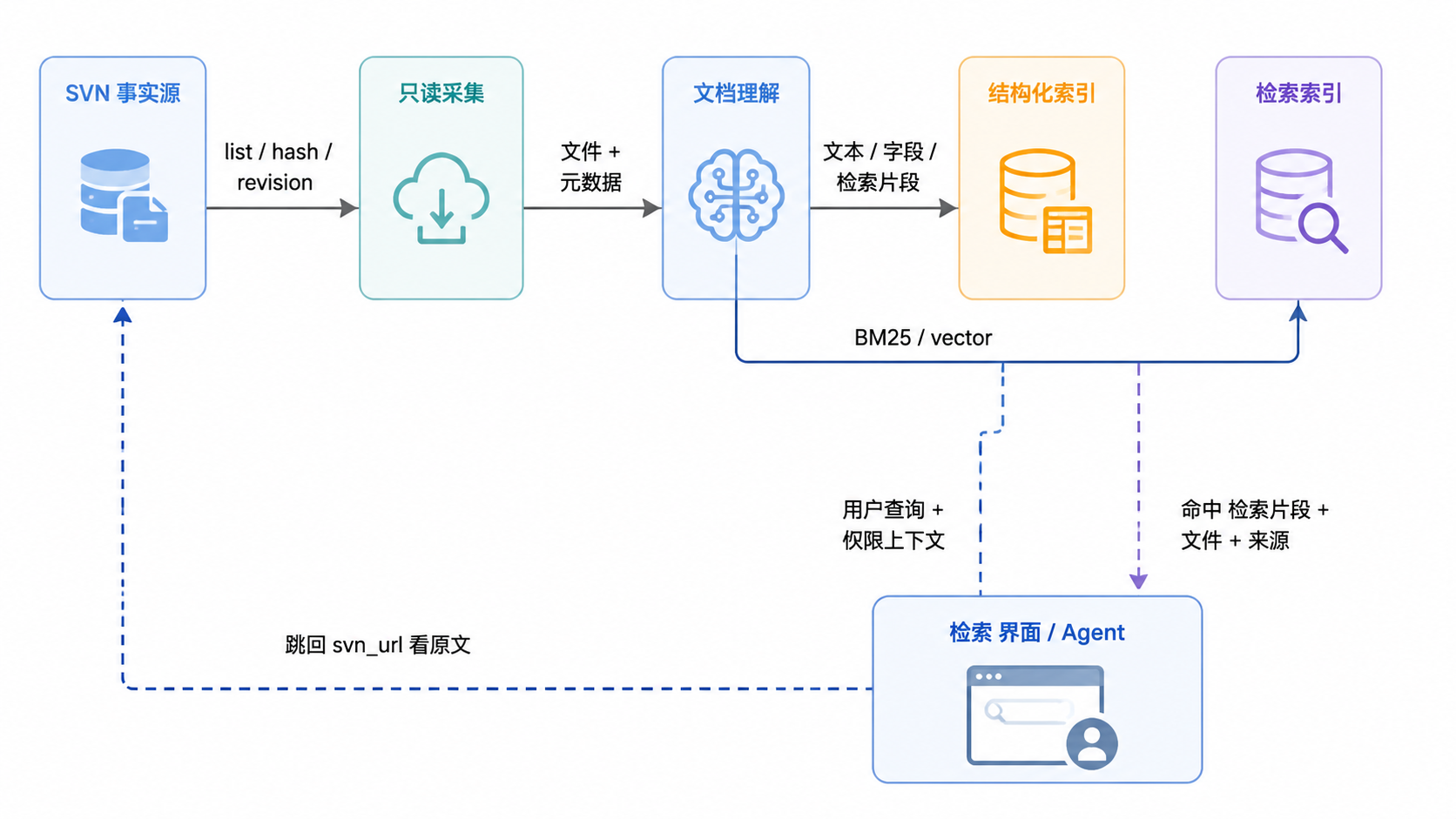
图 1.2 · 事实流。原文不离开 SVN;索引层只持有可检索文本与元数据。
权限流:authz → 检索过滤 → 上下文
一期权限规则的核心是过滤前置:
- authz 解析或以当前用户身份访问 SVN,得到可访问路径。
- 检索查询层和服务中间层都执行过滤,不允许仅在前端隐藏。
- 摘要、命中片段、AI 上下文、原文链接同等过滤。
- 权限变更后旧缓存必须失效或标记过期。
来源
docs/03-baseline-requirements.md §4.2;docs/05-community-discussion-brief.md §10.4。反馈流:AI 建议 → 人审 → 写回结构化索引
AI 不直接写入事实表。所有标签、字段、摘要候选先进入审核队列;人审通过后产生 response,再由审核服务写到生产表,并保留来源、置信度、审计。
不要让 LLM 直接修改事实表
Argilla 式 suggestion → response 的真正作用,是把"模型说什么"和"人确认什么"显式拆开。一旦混在一起,未来很难做评测和回滚。详见 2.2 Argilla 人审反馈。
三档架构选项
主报告把端到端架构拆成三档,分别匹配不同阶段:
| 档位 | 组合 | 资源 | 适合目标 |
|---|---|---|---|
| 低风险原型 | PostgreSQL + MinIO/NAS + pgvector 或 Qdrant + 传统 PDF 解析 / OCR | 低 | 验证入库、标签、检索流程 |
| 企业可用版 | PostgreSQL + MinIO + Qdrant/Milvus/Weaviate + Elasticsearch/Open搜索 + Docling/MinerU/PP-StructureV3 + 重排序 | 中 | 支撑 100GB 到 TB 级资料库 |
| 智能增强版 | + Neo4j 图谱增强检索 + 多模态索引 + 多步 智能体检索 + 自动治理 | 高 | 跨项目洞察、长期知识运营 |
来源
docs/00-main-report.md §5.1。继续阅读
- 1.2 标签体系 · 规则、模型建议和人工确认如何分层。
- 1.3 入库管线 · 把图 1.1 落到具体 ingestion_job 与表。
- 2. 参考项目与分类 · 各平台对应到哪一层。