1.2 标签体系
定义标签数据对象、三段式生成策略(强规则 → 模型建议 → 人审确认)以及配套算法问题清单,确保标签从自动预填到人工确认全链路可评估、可回溯。
相关来源文件
docs/11-reference-platforms-agentic-knowledge-base.md§9 · 标签体系与算法设计。
数据对象
标签子系统围绕以下核心对象构建,所有对象均持有审计字段(created_at / updated_by / source)。
| 对象 | 关键字段 | 说明 |
|---|---|---|
| Tag | id, name, level (L1–L3), parent_id, is_active | 层级标签节点,L1 为业务域,L2 为文档类型,L3 为细粒度主题。 |
| Alias | id, tag_id, alias_name, lang, source | 同一标签的别名/缩写/多语言映射,用于归并与搜索扩展。 |
| Rule | id, pattern (regex/glob), target_tag_id, priority | 强规则:路径/文件名匹配 → 自动预填 L1/L2/L2.5 标签。 |
| 模型建议 | id, document_id, tag_id, confidence, model_version | 模型给出的标签建议,待人审确认。对应 Argilla suggestion。 |
| 人工确认结果 | id, suggestion_id, reviewer_id, action (accept/reject/edit), final_tag_id | 人审结果,确认后写入生产标签关联。对应 Argilla response。 |
| 证据 | id, suggestion_id, snippet, page_no, chunk_id | 模型给出建议时引用的原文证据,便于审核员快速判断。 |
| MergeHistory | id, source_tag_id, target_tag_id, merged_by, merged_at | 标签合并记录,保证引用完整性与可回溯。 |
来源
docs/11-reference-platforms-agentic-knowledge-base.md §9.1。算法问题清单
以下列出标签体系涉及的核心算法问题,按一期优先级排序。
| 算法问题 | 输入 | 输出 | 推荐方法 | 一期优先级 |
|---|---|---|---|---|
| 层级分类 | 文档文本 + 元数据 | L1/L2/L3 标签 | 规则 + 分层 Classifier | P0 |
| 多标签分类 | 文档文本 | 多个 L3 标签 + 置信度 | Multi-label LLM / SetFit | P0 |
| 实体识别 | 文档文本 | 项目名、客户名、标准号等实体 | NER (GLiNER / LLM extraction) | P1 |
| 标签别名归并 | 标签列表 + 别名表 | 合并后的规范标签 | 编辑距离 + Embedding 相似度 | P1 |
| 冲突消解 | 多条规则/模型建议冲突 | 最终标签决策 | 优先级规则 + 人审兜底 | P1 |
| 主动学习 | 低置信度样本池 | 最有价值的待标注样本 | Uncertainty sampling / Committee | P2 |
| 标签漂移检测 | 时间窗口内标签分布 | 漂移告警 + 建议重训 | PSI / KL 散度监控 | P2 |
| 权限感知标签 | 标签 + 用户权限上下文 | 过滤后的标签视图 | 行级过滤 + 聚合脱敏 | P0 |
来源
docs/11-reference-platforms-agentic-knowledge-base.md §9.2。三段式标签生成策略
标签从文件入库到最终生产,经过三个阶段,逐步从高确定性规则到低确定性模型再到人工兜底:
阶段 1:强规则预填
利用 SVN 路径、文件名、目录结构中的确定性信息,通过 Rule 表中的正则/glob 模式自动预填 L1(业务域)、L2(文档类型)、L2.5(子类型)标签。此阶段不依赖模型,准确率要求 ≥95%。
/项目文档/XX项目/设计/→ L1=项目文档, L2=设计文件*-合同-*.pdf→ L2=合同/质量体系/标准/→ L1=质量体系, L2=标准规范
Code
规则引擎参考 paperless-ngx/paperless-ngx ·
匹配核心
src/documents/matching.py(matches、iterable_to_choices);
MatchingModel 抽象与匹配算法字段 src/documents/models.py(MATCH_ANY / MATCH_ALL / MATCH_LITERAL / MATCH_REGEX / MATCH_FUZZY / MATCH_AUTO);
自动学习匹配(朴素贝叶斯)src/documents/classifier.py。
阶段 2:模型建议
对规则未覆盖或需要细粒度标签的文档,调用大语言模型(LLM)或专用分类模型推荐 L3 标签、摘要、实体。输出写入 Suggestion(模型建议)表,附带置信度与 Evidence(证据)。
- LLM 提取:主题标签、关键实体(项目名、客户、标准号)
- SetFit / 微调模型:多标签分类,输出 Top-N 候选 + 置信度
- 所有建议均不直接写入生产表
阶段 3:人审确认
审核员在 Argilla 式界面中查看 suggestion + evidence,执行 accept / reject / edit 操作,产生 人工确认结果。确认后的标签写入生产关联表,同时记录审计信息。
Code
模型建议 / 人工确认 模型参考 argilla-io/argilla ·
记录 / 模型建议 / 人工确认 数据模型
argilla/src/argilla/_models/_record/;
Question 类型(LabelQuestion / MultiLabelQuestion)argilla/src/argilla/settings/_question.py;
Server 端记录 / 建议 / 响应表 argilla-server/src/argilla_server/models/database.py。
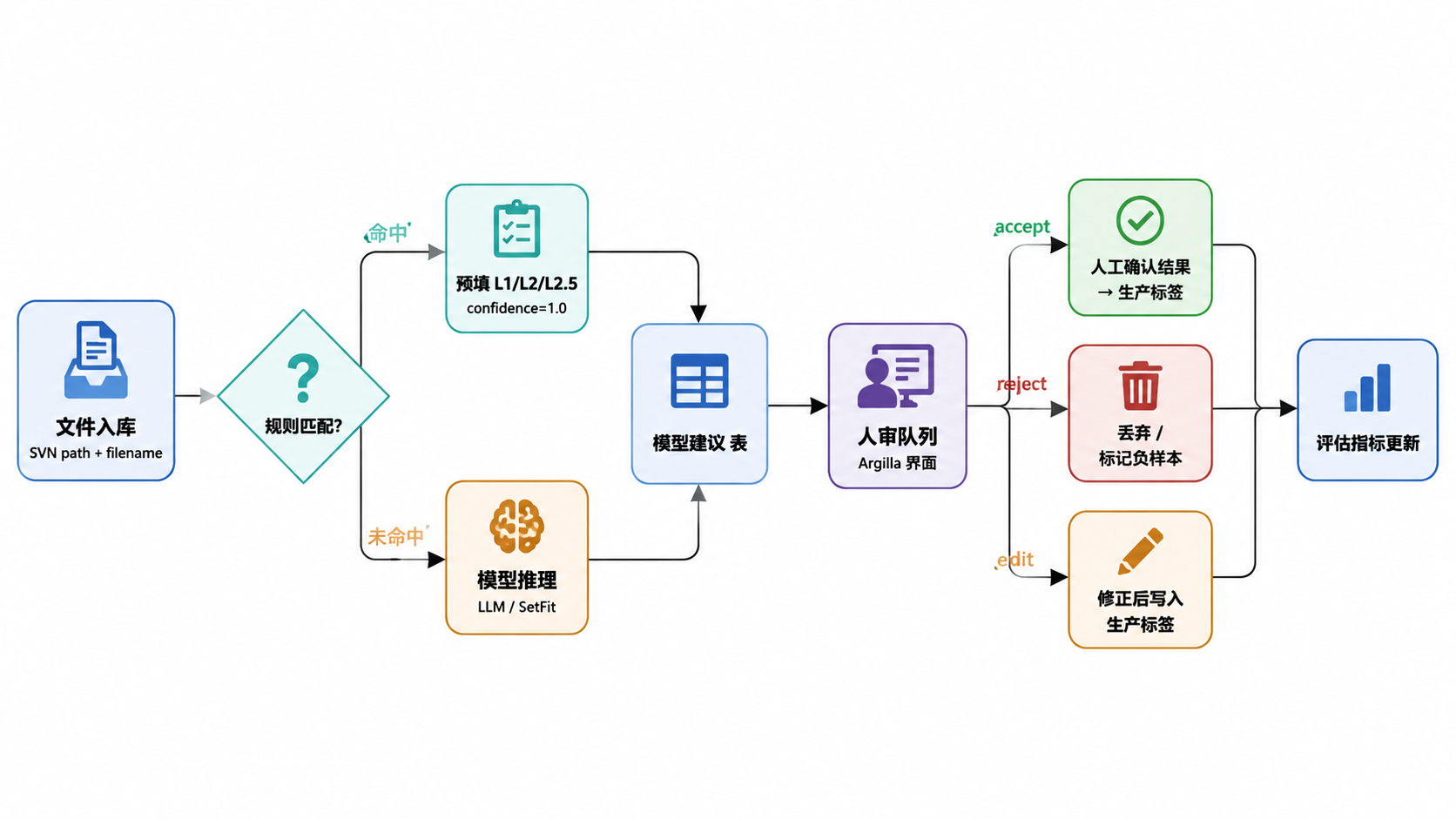
图 3.1 · 三段式标签生成流水线。强规则 → 模型建议 → 人审确认,逐步降低不确定性。
来源
docs/11-reference-platforms-agentic-knowledge-base.md §9.3。评估指标
所有指标在每次模型版本更新和每月运营复盘时统计;不达标的模块阻断上线。
| 指标 | 目标值 | 统计口径 |
|---|---|---|
| L1 / L2 自动预填准确率 | ≥ 95% | 抽样 500 份文件,规则预填结果与人工金标对照 |
| L3 Top-5 召回率 | ≥ 85% | 金标 L3 标签是否落在模型 Top-5 候选中 |
| 人工修改率 | 持续下降 | (edit + reject) / total response,按月环比 |
| 新标签误增率 | ≤ 5% | 同期新增标签中被合并/废弃的占比 |
| 标签合并后引用完整率 | 100% | MergeHistory 后所有引用是否仍可解析到目标 tag |
| 权限标签泄露 | 0 | 未授权用户能否通过标签计数推断敏感文档存在 |
来源
docs/11-reference-platforms-agentic-knowledge-base.md §9.4。权限感知标签
权限感知标签:标签计数也是信息泄露面
"无权限的用户不应通过标签计数推断敏感材料存在"——这是一期硬性约束。常见反模式:
- 标签云显示
并购方案 (12),但当前用户无任何并购文档权限 → 已经泄露 12 份敏感文档存在的事实。 - 搜索建议下拉中出现
客户XX-诉讼字样 → 即使点击后被拒绝,标签字面已经泄露主题。 - 标签筛选器返回零命中但仍显示该标签 → 暴露权限边界。
正确做法:标签视图必须先按用户权限过滤可见文档,再聚合计数;零命中标签从下拉与筛选器中物理移除;审计日志记录权限受限的标签访问尝试。
继续阅读
- 2.2 Argilla 人审反馈 · 模型建议 / 人工确认 / evidence 的具体协议与界面。
- 1.3 入库管线 · 标签表与 ingestion_job 如何衔接。