2.5.5 RAGFlow
企业资料包含扫描件、表格、合同、政策、混排 PDF,简单切块会丢失版面、表格和证据位置。
业务需求深度文档理解与引用检索
架构位置作为复杂文档解析、片段可视化、引用优先回答的算法和界面参照
落地阶段二期算法验证
相关来源文件
ai_agent_huge_data_report/docs/13-reference-projects-deepwiki-granularity.mdai_agent_huge_data_report/docs/11-reference-platforms-agentic-knowledge-base.md
DeepWiki 中文译文子页
RAGFlow 的 DeepWiki 中文译文入口
处理扫描件、表格、合同、政策、混排 PDF,避免简单切块丢失版面、表格和证据位置。
62/62 页中文译文
译文覆盖完整
系统架构、界面与交互、检索、召回与索引
业务问题与适用场景
企业资料包含扫描件、表格、合同、政策、混排 PDF,简单切块会丢失版面、表格和证据位置。
本页从 RAGFlow 中拆出问题解决方式、对象边界、关键机制和可迁移设计,避免“看过一个开源项目”停留在名词层面。
架构位置与边界
作为复杂文档解析、片段可视化、引用优先回答的算法和界面参照。
落地判断
如果该项目能力进入本项目,必须先回答三件事:是否保留现有事实源,是否能继承权限,是否能把每个结论回到来源证据。核心对象与数据模型
| 对象 | 作用 | 本项目映射 |
|---|---|---|
数据Dataset | 一组资料或业务资料域。 | knowledge_collections |
文档Document | 导入并解析的原始资料。 | documents |
解析器Parser | 按版面、表格、扫描件和文本类型提取内容。 | parser_runs |
检索片段Chunk | 可召回、可引用、可定位的最小证据单元。 | document_chunks |
切分方法Chunk Method | 按合同、政策、表格、问答等采用不同切分策略。 | chunking_profiles |
引用Citation | 回答中绑定文件、页码、区域和片段编号。 | citations |
主流程与数据流
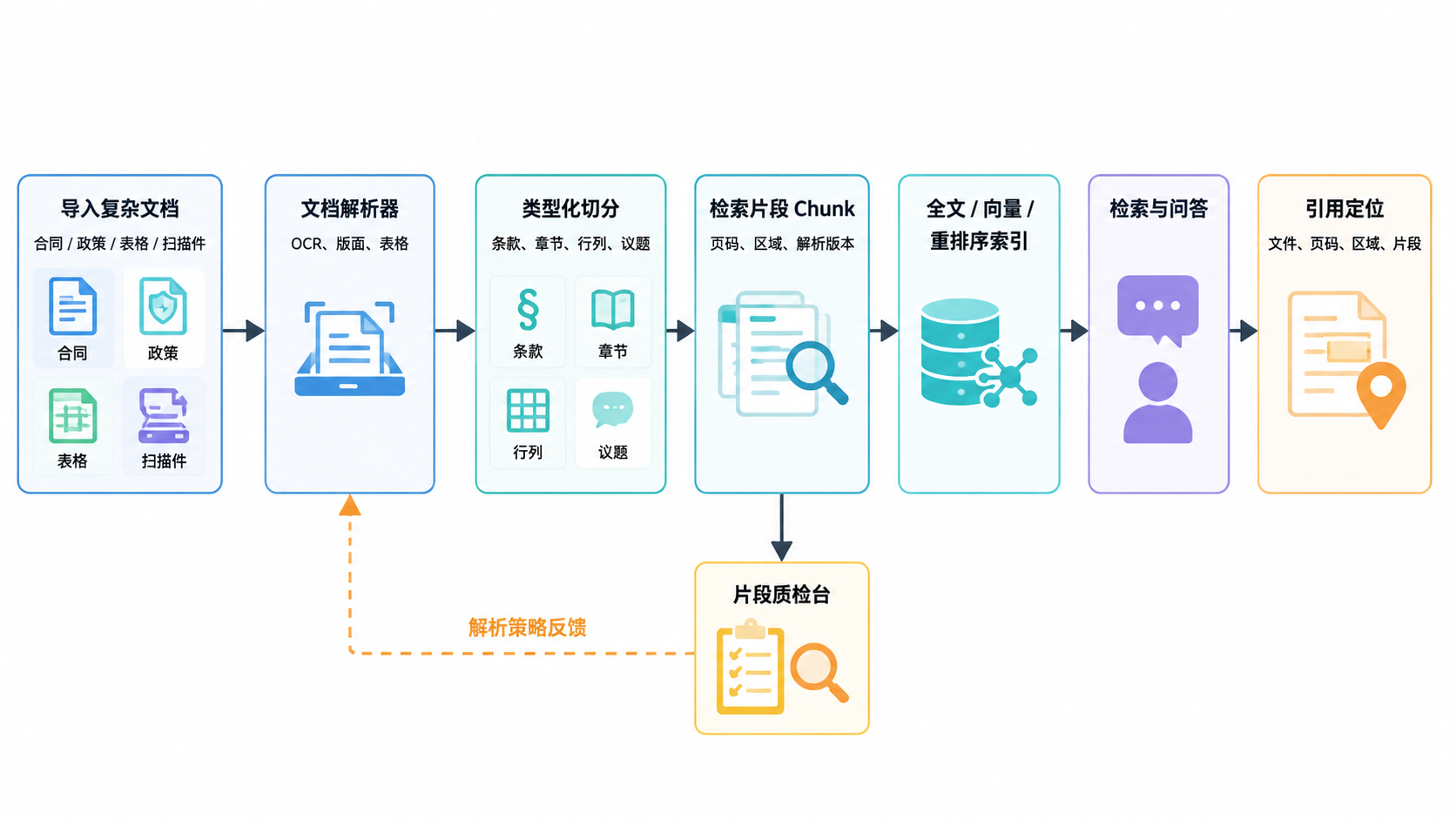
图 2.5.5 · RAGFlow 主流程与数据流。
关键实现机制
| 机制 | 拆解说明 |
|---|---|
| 片段可视化 | 每个检索结果都能回到页码、框选区域或表格单元。 |
| 解析版本化 | 同一文档用不同解析器版本处理时必须可比较、可回滚。 |
| 类型化切分 | 政策按条款,合同按章节和义务,表格按行列语义,会议纪要按议题切分。 |
| 引用优先生成 | 先确认证据片段,再组织自然语言回答。 |
技术亮点
- 对复杂 PDF 和表格场景更贴近企业资料实际。
- 片段检查界面能暴露解析质量问题项
- 引用定位机制是减少幻觉的关键。
不适合照搬的部分
- 不应替代生产事实库。
- 解析效果高度依赖资料类型,必须建立本地评测集。
映射到本项目
| 本项目设计点 | 落地说明 |
|---|---|
| 片段质检台 | 展示片段文本、页码、区域、解析器版本和来源路径。 |
| 解析策略库 | 按资料类型配置切分参数和抽取规则。 |
| 引用服务 | 所有问答结论返回可点击证据。 |
验证清单
- 构造合同、政策、扫描件、表格各 50 份评测集。
- 评价片段完整性、表格保真度、引用定位准确率和回答证据覆盖率。
依据
术语显示规则
- 正文
- 优先使用中文术语;项目名、接口名和代码字段保留原名。
- 原名
- 原英文名以灰色代码标识显示,便于索引和核对定义,不打断常规阅读。
下一页2.5.6 Onyx