1.3 入库管线
从"选择 SVN 文件"到"可检索、可引用、可跳回原文"的完整数据流,以及推荐的核心表结构。
相关来源文件
docs/11-reference-platforms-agentic-knowledge-base.md· §10 入库与数据库写入设计。docs/03-baseline-requirements.md· §3 一期核心功能、§4 数据与权限基线。docs/00-main-report.md· §1 PDF 管道建议、§2.3 推荐数据组织格式。
入库管线流程
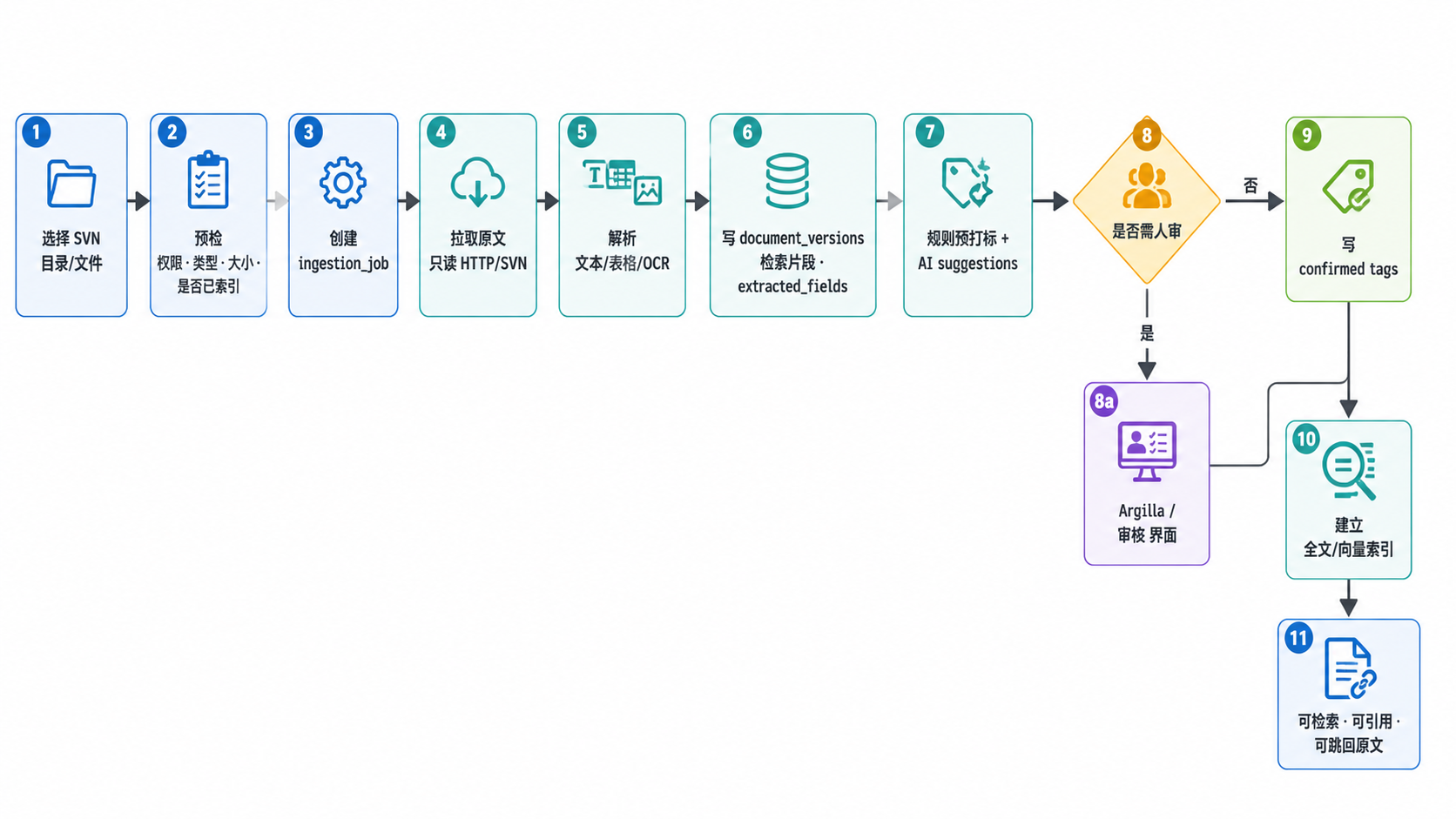
图 4.1 · 入库管线。每一步都有状态记录,失败可重试。
Code
paperless-ngx/paperless-ngx ·
消费 / 任务编排
src/documents/consumer.py、src/documents/tasks.py;
解析器注册与路由 src/documents/parsers.py;
全文索引与查询 src/documents/index.py;
文档模型 src/documents/models.py。
ingestion_job 状态机
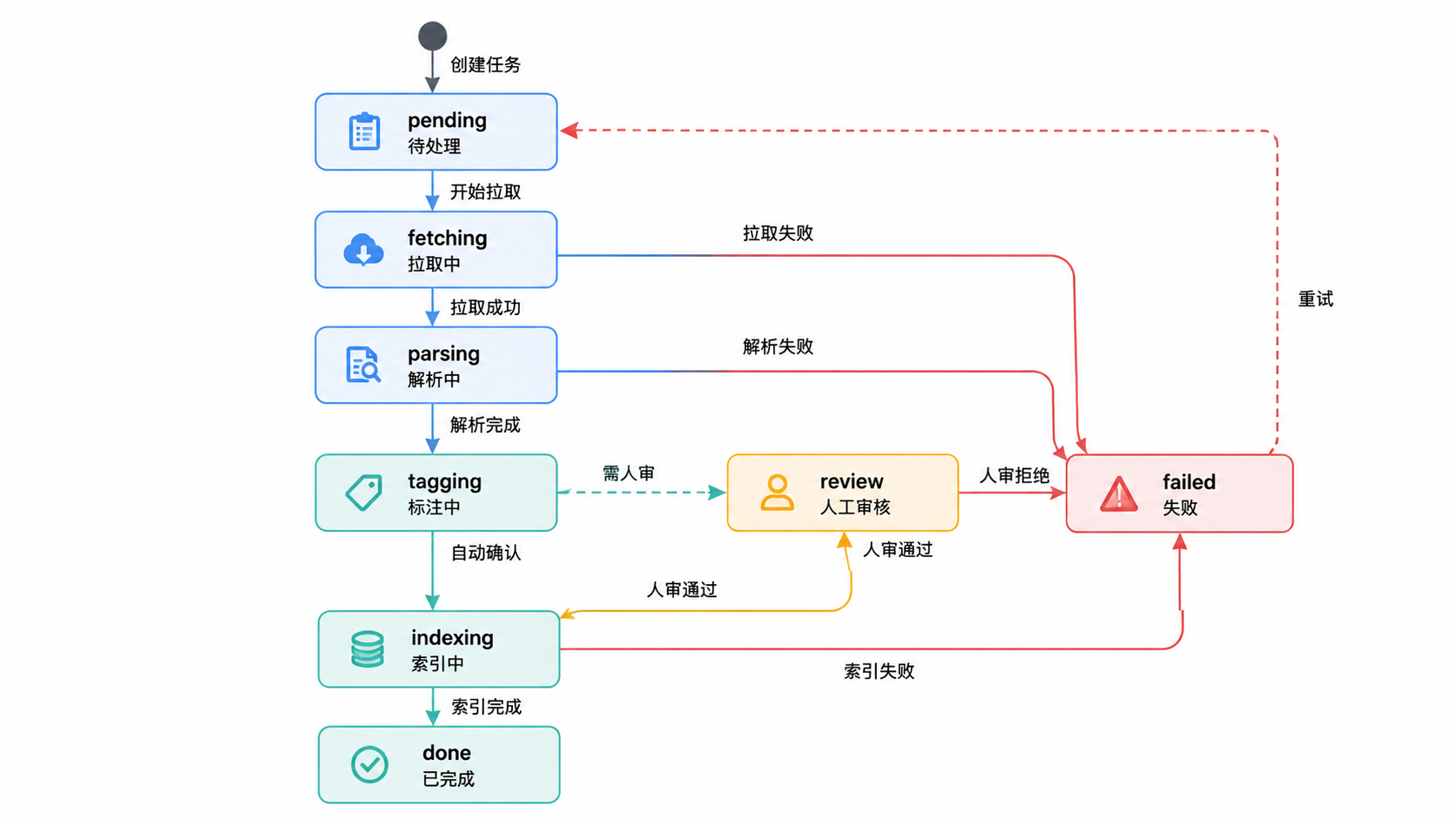
图 4.2 · ingestion_job 状态机。failed 可重试回到 pending。
来源
docs/11-reference-platforms-agentic-knowledge-base.md §10.1。推荐核心表
| 表 | 核心字段 | 说明 |
|---|---|---|
documents | id · svn_path · svn_url · file_name · file_type · business_doc_id · status · permission_scope · created_at | 一份业务文档的容器 |
document_versions | id · document_id · svn_revision · source_kind · hash · parser_version · active · created_at | Word / 盖章 PDF / OCR / 人工修正稿 |
document_chunks | id · version_id · chunk_index · text · page · bbox · heading_path · token_count · quality_score | 可检索片段,必须有页码或位置 |
extracted_fields | id · document_id · field_key · value · confidence · source_chunk_id · review_status | 合同金额、客户名、期限等 |
tags | tag_key · name · level · parent_key · status · scope · description | 标签字典 |
tag_aliases | alias · tag_key · match_type · status | 别名、同义词、旧称 |
document_tags | document_id · tag_key · source · confidence · review_status · evidence_chunk_id | 文档-标签关系 |
review_tasks | id · task_type · object_type · object_id · payload · assignee · status · result_ref | 人审任务队列 |
permissions | subject · svn_path_prefix · permission · source · updated_at | 权限映射 |
search_audit_logs | user · query · filters · returned_doc_ids · tool_trace_id · created_at | 检索审计 |
关键设计原则
document_versions.source_kind区分 word / pdf / ocr / human_correction。document_tags.source区分 path_rule / model_suggestion / human_response / migration。review_status区分 suggested / confirmed / rejected / needs_review。- 权限过滤必须在检索接口层和 SQL/索引查询层执行。
来源
docs/11-reference-platforms-agentic-knowledge-base.md §10.2。解析路由策略
| 文件类型 | 优先解析方式 | 失败回退 |
|---|---|---|
| Word (.docx) | python-docx 提取正文 + 表格 | 标记需人工处理 |
| Excel (.xlsx) | openpyxl 结构化读取 | 不走 OCR(除非截图型) |
| 数字 PDF | PyMuPDF / pdfplumber 文本提取 | 乱码或空文本时转 OCR |
| 扫描 PDF | 页面转图片 → PaddleOCR | 标记低置信度页面 |
| 图片 | PaddleOCR + 可选图片说明 | 无文字时只保存标签和简介 |
| 合同 Word 留档 | 优先提取正文、表格、字段候选 | 记录对应盖章件路径 |
| 合同盖章件 | 作为签署证据,OCR 后与 Word 做差异提示 | 字段以人工确认为准 |
来源
docs/03-baseline-requirements.md §5.2;docs/00-main-report.md §1.3。开源参考实现
本节给出可直接拿来做对照、抽样评测、或深度借鉴解析策略的开源项目。粒度到模块 / 文件级,方便按需深入。
| 项目 | 定位 | 关键模块 | 本项目用途 |
|---|---|---|---|
| DS4SD/docling | 统一的多格式文档转换器,输出层级化 DoclingDocument | docling/document_converter.py、docling/pipeline/、docling/backend/、docling/datamodel/document.py |
PDF / Word / 表格的统一抽象与版面理解的对照实现 |
| opendatalab/MinerU | 面向中文复杂版式 PDF 的解析(公式 / 表格 / 阅读顺序) | magic_pdf/pipe/、magic_pdf/model/、magic_pdf/post_proc/ |
政策 / 合同 / 评审报告类高难版面的二期 验证 候选 |
| PaddlePaddle/PaddleOCR | 中文 OCR 与 PP-StructureV3 版面 / 表格识别 | ppocr/(检测 / 识别)、ppstructure/(版面 / 表格 / 公式 / KIE) |
盖章件、扫描历史档、图片资料的一期主力 OCR |
| Unstructured-IO/unstructured | 面向 RAG 的多格式 partition 工具集 | unstructured/partition/(pdf.py / docx.py / xlsx.py / html.py / image.py)、unstructured/检索片段ing/ |
多格式入库的对照实现 + 检索片段策略借鉴 |
| infiniflow/ragflow | 带模板化切块 / 引用的 检索增强生成引擎 | deepdoc/parser/、deepdoc/vision/、rag/app/ |
切块策略与引用机制的二期借鉴 |
| paperless-ngx/paperless-ngx | 消费管道 + 自动匹配 + 全文索引 | src/documents/consumer.py、src/documents/tasks.py、src/documents/index.py、src/documents/parsers.py |
ingestion_job 状态机与全文索引层的参考 |
如何用这些参考实现
- 评测对照:用 Docling / MinerU / Unstructured 在同一份脱敏样本上跑解析,记录 Word 提取率、表格保真率、空文本率,作为本项目解析路由的基线。
- 策略借鉴:把 Paperless 的 消费任务 + 匹配规则、RAGFlow 的模板化切块、Unstructured 的 检索片段ing 策略落到本项目的 入库模块。
- 不照搬框架:仅复用单点能力(如 PaddleOCR 的 PP-StructureV3)作为子任务,避免引入整套 Web 应用栈。
继续阅读
- 1.2 标签体系 · 规则预打标和 AI suggestion 的具体算法。
- 2.2 Argilla 人审反馈 · 人审队列如何接入。
- 1.4 路线图 · 入库管线在一期的工作量与关口。