2.5.1 Paperless-ngx
把分散文件稳定纳入可检索、可归档、可自动分类的资料库,同时保留原件和处理痕迹。
业务需求文档归档与消费管道
架构位置位于入库后的文档消费层,负责文件接收、文字识别、自动匹配、标签化和归档展示,不替代 SVN 或企业事实库
落地阶段一期可借鉴
相关来源文件
ai_agent_huge_data_report/docs/13-reference-projects-deepwiki-granularity.mdai_agent_huge_data_report/docs/11-reference-platforms-agentic-knowledge-base.md
DeepWiki 中文译文子页
Paperless-ngx 的 DeepWiki 中文译文入口
把分散文件稳定纳入可检索、可归档、可自动分类的资料库,同时保留原件和处理痕迹。
22/22 页中文译文
译文覆盖完整
文档对象与元数据、系统架构、界面与交互
业务问题与适用场景
把分散文件稳定纳入可检索、可归档、可自动分类的资料库,同时保留原件和处理痕迹。
本页从 Paperless-ngx 中拆出问题解决方式、对象边界、关键机制和可迁移设计,避免“看过一个开源项目”停留在名词层面。
架构位置与边界
位于入库后的文档消费层,负责文件接收、文字识别、自动匹配、标签化和归档展示,不替代 SVN 或企业事实库。
落地判断
如果该项目能力进入本项目,必须先回答三件事:是否保留现有事实源,是否能继承权限,是否能把每个结论回到来源证据。核心对象与数据模型
| 对象 | 作用 | 本项目映射 |
|---|---|---|
文档Document | 已入库的可检索文档,是归档、预览、全文检索和标签关系的中心对象。 | documents / document_versions |
标签Tag | 用多标签表达业务主题,避免把所有分类语义塞进目录层级。 | tags / document_tags |
往来方Correspondent | 原系统偏个人文档往来对象,本项目可扩展为客户、政府单位、合同主体、我方主体。 | parties / organizations |
文档类型Document Type | 区分合同、发票、政策、评审材料、会议纪要等处理模板。 | document_types |
自定义字段Custom Field | 承载金额、日期、项目编号、政策文号等结构化抽取结果。 | document_fields |
工作流Workflow | 基于事件触发自动赋值、路由或人工复核。 | ingestion_jobs / review_tasks |
主流程与数据流
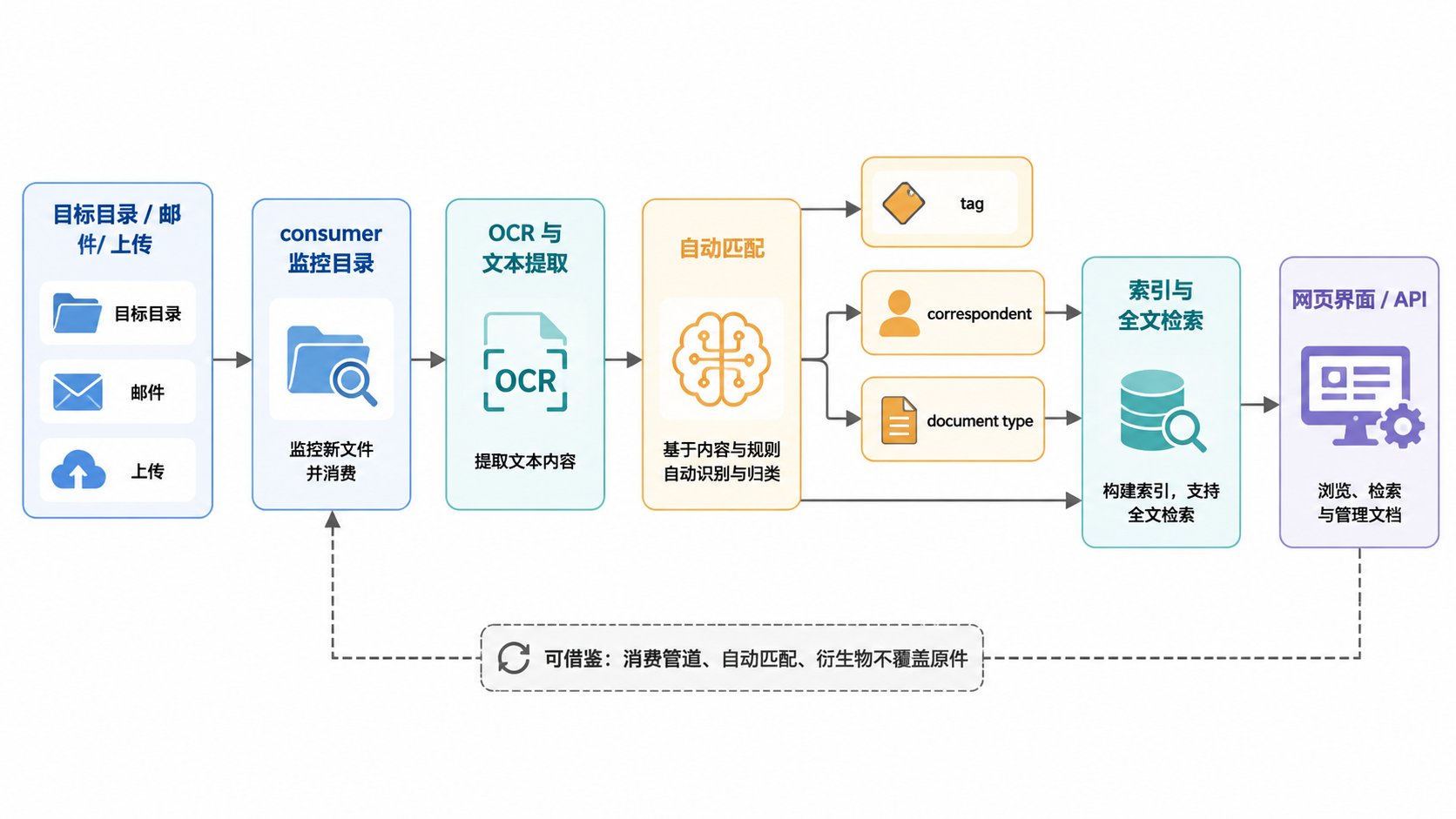
图 2.5.1 · Paperless-ngx 主流程与数据流。
关键实现机制
| 机制 | 拆解说明 |
|---|---|
| 消费目录思想 | 把文件进入系统的动作抽象成任务队列,支持失败重试、重复文件检测、处理状态追踪。 |
| 规则优先的自动匹配 | 路径、文件名、固定关键词先行,模型只补充低置信候选,降低自动打标污染。 |
| 原件不覆盖 | 原始文件、解析文本、清洗文本、摘要、缩略图、向量和索引分别保存来源关系。 |
| 标签独立建模 | 标签需要作为可治理、可合并、可禁用、可追溯的业务词表独立维护。 |
技术亮点
- 小团队文档归档体验成熟,适合借鉴入库和自动匹配细节。
- 保留原件与衍生物关系,符合资料审计和回溯需要。
- 标签、往来方、文档类型组合形成轻量语义层。
不适合照搬的部分
- 往来方模型偏个人归档,需要扩展成企业主体和项目主体。
- 不适合直接作为权限事实源,也不应接管 SVN 历史。
映射到本项目
| 本项目设计点 | 落地说明 |
|---|---|
| 入库任务表 | 记录文件来源、修订号、处理状态、错误、重试次数和处理器版本。 |
| 标签候选表 | 区分规则建议、模型建议、人工确认结果。 |
| 文档衍生物表 | 保存原件、识别文本、清洗文本、预览图、摘要和向量之间的来源关系。 |
验证清单
- 随机抽取 200 份 SVN 文件,检查重复识别率、解析成功率、低置信转人工比例。
- 用 20 个高频目录验证规则打标准确率,低于阈值不得自动入事实表。
依据
术语显示规则
- 正文
- 优先使用中文术语;项目名、接口名和代码字段保留原名。
- 原名
- 原英文名以灰色代码标识显示,便于索引和核对定义,不打断常规阅读。