架构总览
架构总览
相关源文件
本章引用的主要源码文件:
.editorconfig.pre-commit-config.yamlDockerfiledocs/administration.mddocs/advanced_usage.mddocs/api.mddocs/changelog.mddocs/configuration.mddocs/development.mddocs/faq.mddocs/index.mddocs/setup.mddocs/troubleshooting.mddocs/usage.mdpyproject.tomlsrc-ui/package.jsonsrc-ui/src/environments/environment.prod.tssrc-ui/src/environments/environment.tssrc/documents/context_processors.pysrc/documents/static/base.csssrc/documents/templates/paperless-ngx/base.htmlsrc/paperless/__init__.pysrc/paperless/adapter.pysrc/paperless/checks.pysrc/paperless/tests/test_adapter.pysrc/paperless/tests/test_checks.pysrc/paperless/tests/test_utils.pysrc/paperless/tests/test_views.pysrc/paperless/utils.pysrc/paperless/version.pyuv.lock
本文档对 Paperless-ngx 的系统架构、其组件以及它们之间的交互方式进行了高层级概述。它作为理解系统数据流和实现细节的技术基础。
系统概览
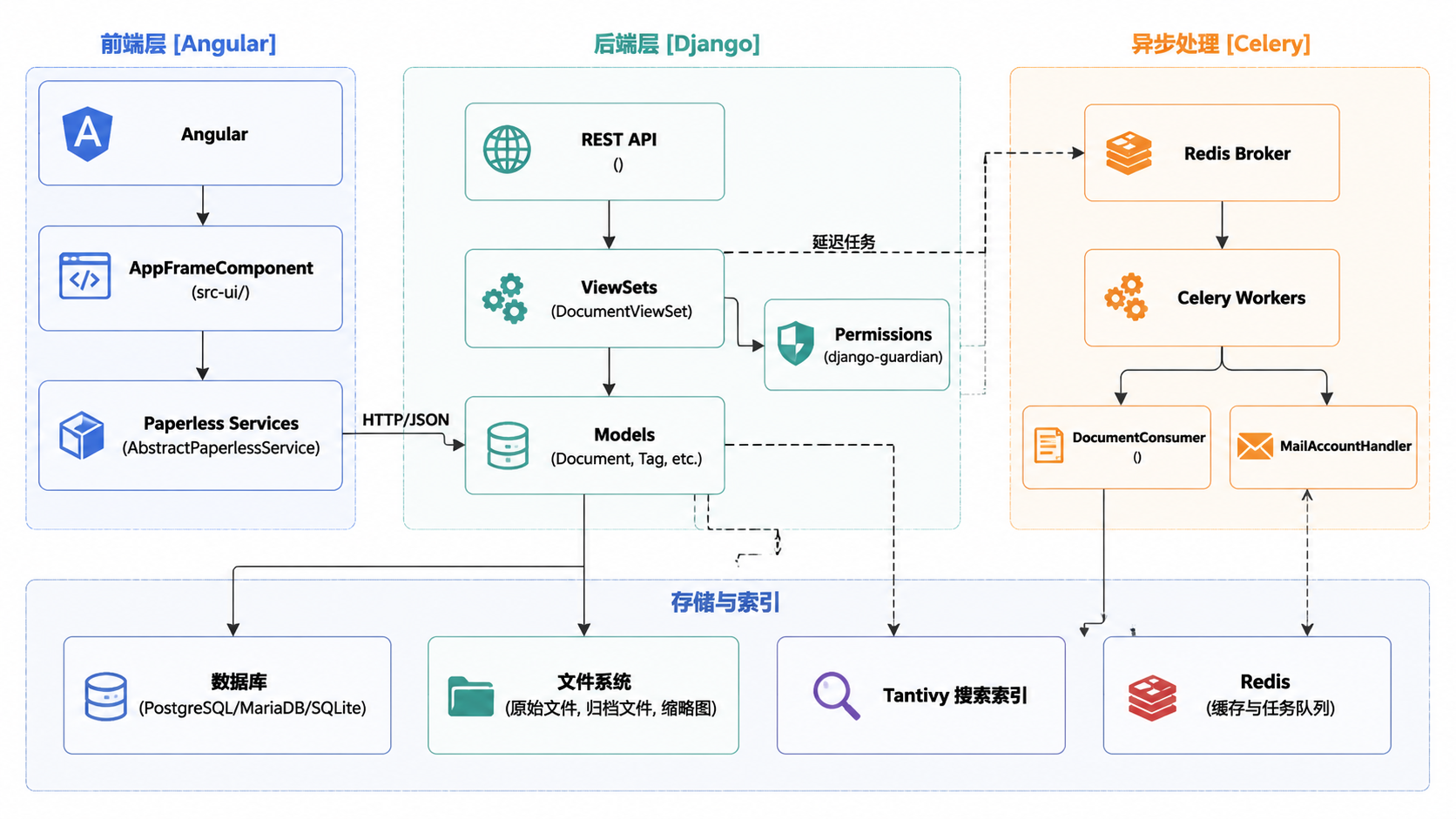
Paperless-ngx 是一个文档管理系统,能将实体文档转换为可搜索的数字档案。该系统采用分布式架构,包含一个单页应用(SPA)前端、一个基于 Django 的 REST API、一个异步任务队列以及多个存储和索引层。
来源:src-ui/src/environments/environment.prod.ts:1-13, Dockerfile:118-158, docs/configuration.md:27-50, docs/usage.md:14-53
核心组件
前端(Angular)
前端是一个基于 TypeScript 的 SPA,使用 Angular 构建。它通过一个版本化的 REST API(当前版本为 10)与 Django 后端通信。
- 环境:配置通过
environment.prod.ts管理,该文件定义了apiBaseUrl和用于实时状态更新的 WebSocket 设置。src-ui/src/environments/environment.prod.ts:3-13 - 依赖:使用
@angular/material构建 UI 组件,pdfjs-dist用于文档预览,ngx-cookie-service用于会话管理。src-ui/package.json:13-41
后端(Django)
后端提供业务逻辑、元数据管理和 API 端点。
- REST API:使用 Django REST Framework(DRF)构建,利用
ViewSets处理标准的 CRUD 操作以及诸如bulk_edit或post_document等自定义操作。docs/api.md:1-50 - 认证:集成了
django-allauth用于登录/登出和多因素认证(MFA)支持。docs/changelog.md:11-12,pyproject.toml:28-28 - 并发:通过
granian或gunicorn(在 webserver 可选依赖中)以及使用 Celery 进行异步任务处理来管理并发。pyproject.toml:20-20,pyproject.toml:93-95
任务队列(Celery 与 Redis)
异步操作被卸载到 Celery 工作进程上执行,以防止阻塞 Web 服务器。
- 消息代理:Redis 是 Celery 的主要消息代理,也是 Django Channels(WebSocket)的后端。
docs/configuration.md:27-44 - 任务:包括文档入库、邮件抓取和索引优化。
docs/configuration.md:29-31
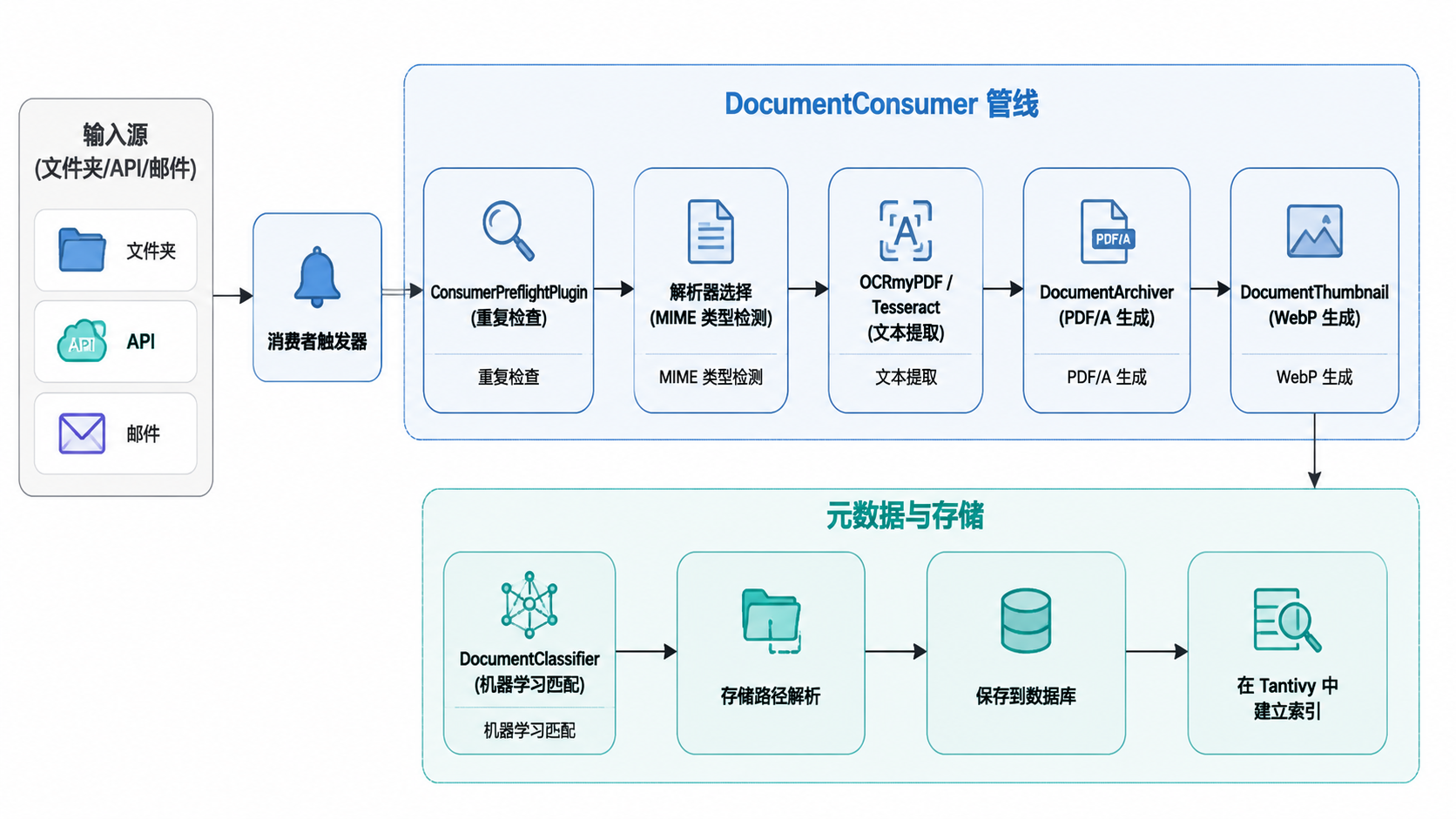
文档处理管线
文档处理管线负责将原始文件转换为完全索引的文档。
来源:docs/usage.md:120-148, Dockerfile:137-157, pyproject.toml:61-61
关键实现细节
- OCR 引擎:使用
OCRmyPDF(基于 Tesseract)提取文本并生成可搜索的 PDF/A 文件。pyproject.toml:61-61,Dockerfile:138-144 - 搜索引擎:已迁移至 Tantivy(通过
tantivy-py)以实现高性能全文搜索,取代了旧的索引后端。pyproject.toml:76-76 - 分类:使用
scikit-learn实现“自动”匹配算法,该算法基于现有文档元数据训练模型。pyproject.toml:73-73
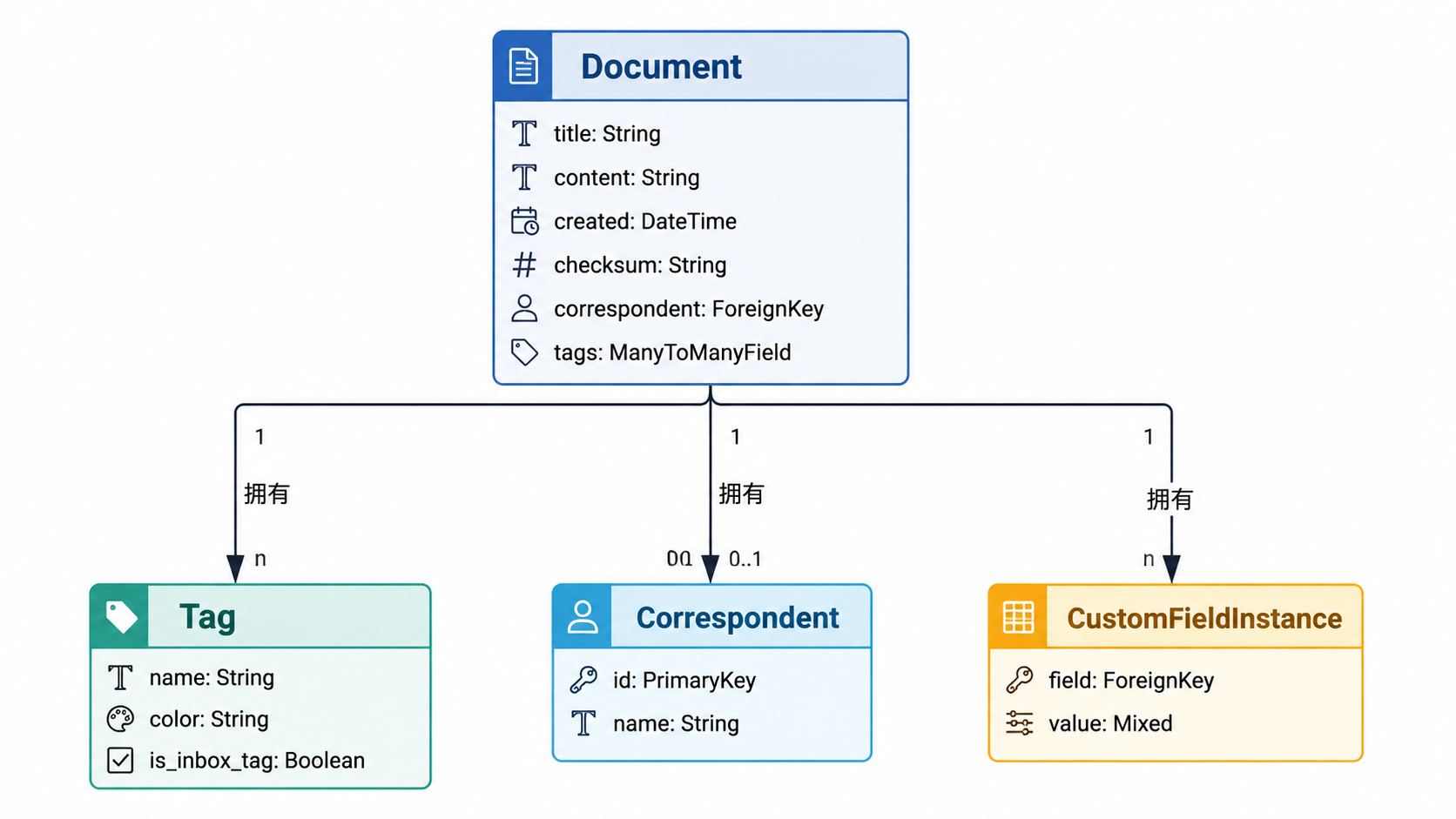
数据模型与存储
Paperless-ngx 严格区分文件存储和元数据。
| 组件 | 代码实体 | 存储位置 |
|---|---|---|
| 元数据 | Document 模型 | db.sqlite3 / PostgreSQL / MariaDB |
| 原始文件 | Document.filename | PAPERLESS_ORIGINALS_DIR |
| 归档文件 | Document.archive_filename | PAPERLESS_ARCHIVE_DIR |
| 搜索索引 | Tantivy 索引 | PAPERLESS_DATA_DIR/index |
来源:docs/usage.md:22-53, docs/configuration.md:53-67, docs/administration.md:36-43
安全与权限
- 对象级权限:通过
django-guardian实现,允许向特定用户或用户组授予对单个文档的view或change权限。pyproject.toml:35-35 - 所有权:每个文档都可以有一个
owner(所有者)。非所有者需要被明确授予权限才能访问或修改文档。docs/changelog.md:31-31 - 隔离:Docker 镜像支持无根执行,并通过
gosu和s6-overlay实现权限降级。Dockerfile:123-123,Dockerfile:33-42
部署架构
标准部署使用 Docker Compose 来编排多个容器:
- Web 服务器/工作进程:运行 Django 和 Celery 的主
paperless-ngx镜像。 - 数据库:PostgreSQL(推荐)、MariaDB 或 SQLite。
- 消息代理:Redis。
- 可选附加组件:用于处理 Office 文档(.docx, .xlsx 等)的 Tika 和 Gotenberg。
来源:docs/setup.md:15-32, docs/setup.md:70-105, docs/configuration.md:11-21