LLM 后端与嵌入
大语言模型后端与嵌入向量
相关源文件
以下文件为本维基页面的生成提供了上下文:
src/documents/management/commands/document_llmindex.pysrc/paperless/settings/__init__.pysrc/paperless_ai/client.pysrc/paperless_ai/embedding.pysrc/paperless_ai/indexing.pysrc/paperless_ai/tests/test_ai_indexing.pysrc/paperless_ai/tests/test_client.pysrc/paperless_ai/tests/test_embedding.py
Paperless-ngx 中的 AI 子系统提供了与大语言模型(LLM)的集成能力,用于元数据提取和文档检索。本页详细介绍了大语言模型后端通信的技术实现、向量嵌入管线以及基于 FAISS 的向量存储管理。
来源:src/paperless_ai/client.py:1-15,src/paperless_ai/embedding.py:1-16
大语言模型后端
AIClient 类是与大语言模型交互的主要接口。它通过 llama-index 库对底层后端进行了抽象。
AIClient 实现
客户端使用 AIConfig 中的配置进行初始化。它支持 LLMBackend 中定义的两种主要后端类型:
- Ollama:用于本地大语言模型执行。默认地址为
http://localhost:11434,默认模型为llama3.1。 - OpenAI 兼容:支持 OpenAI 及其兼容 API(例如 LocalAI、vLLM)。该后端支持函数调用和聊天特定功能。
安全性与校验
所有发往大语言模型端点的出站 HTTP 请求都会通过 validate_outbound_http_url 进行校验。默认情况下,内部/私有网络地址会被阻止,除非启用了 PAPERLESS_LLM_ALLOW_INTERNAL_ENDPOINTS。
| 后端 | 代码实体 | 默认模型 | 配置依赖 |
|---|---|---|---|
| Ollama | llama_index.llms.ollama.Ollama | llama3.1 | PAPERLESS_LLM_ENDPOINT |
| OpenAI 兼容 | llama_index.llms.openai_like.OpenAILike | gpt-3.5-turbo | PAPERLESS_LLM_API_KEY |
来源:src/paperless_ai/client.py:18-58,src/paperless_ai/client.py:60-93,src/paperless/network.py:12-12
文档嵌入向量
嵌入向量是将文档文本和元数据转换为高维向量的过程,用于语义搜索和检索增强生成(RAG)。
嵌入向量模型
系统支持两种嵌入向量后端:
- OpenAI 兼容:使用远程嵌入向量 API。默认模型为
text-embedding-3-small。 - HuggingFace:使用本地句子变换模型。默认模型为
sentence-transformers/all-MiniLM-L6-v2。
维度管理
嵌入向量的维度会在首次初始化时通过对字符串"test"执行"虚拟"嵌入向量来自动检测。这些维度信息以及模型名称会持久化存储在 LLM_INDEX_DIR/meta.json 中。如果配置的模型发生变更,系统会抛出 RuntimeError 以防止索引损坏。
来源:src/paperless_ai/embedding.py:18-47,src/paperless_ai/embedding.py:49-80
向量存储管理(FAISS)
Paperless-ngx 使用 FAISS(Facebook AI 相似度搜索)作为其向量数据库。存储架构通过 llama-index 的 StorageContext 进行管理。
存储组件
LLM_INDEX_DIR 目录包含以下内容:
- 向量存储:
default__vector_store.json(FAISS 索引)。 - 文档存储:
docstore.json(将节点 ID 映射到元数据)。 - 索引存储:
index_store.json。 - 元数据:
meta.json(存储嵌入向量模型和维度)。
索引维护
由于 FAISS IndexFlatL2 实现是仅追加的,更新文档需要遵循特定的工作流:
- 识别
docstore中与某个document_id关联的所有BaseNode对象。 - 从
docstore中删除这些节点。 - 将新节点追加到索引中。
来源:src/paperless_ai/indexing.py:52-88,src/paperless_ai/indexing.py:148-163,src/paperless_ai/indexing.py:164-168
大语言模型索引管线
该管线将 Django Document 模型转换为可搜索的向量节点。
文档到文本的转换
build_llm_index_text 函数将文档序列化为结构化的文本块,供大语言模型使用。它包含以下内容:
- 标准元数据(标题、文件名、日期)。
- 关系数据(标签、通信方、文档类型)。
- 自定义字段和用户备注。
- 文档的完整 OCR 内容。
索引构建与刷新流程
update_llm_index 函数同时处理完全重建和增量更新。
数据流:从文档到向量存储
下图展示了从 Django 模型空间到向量索引空间的转换过程。
文档向量化流程
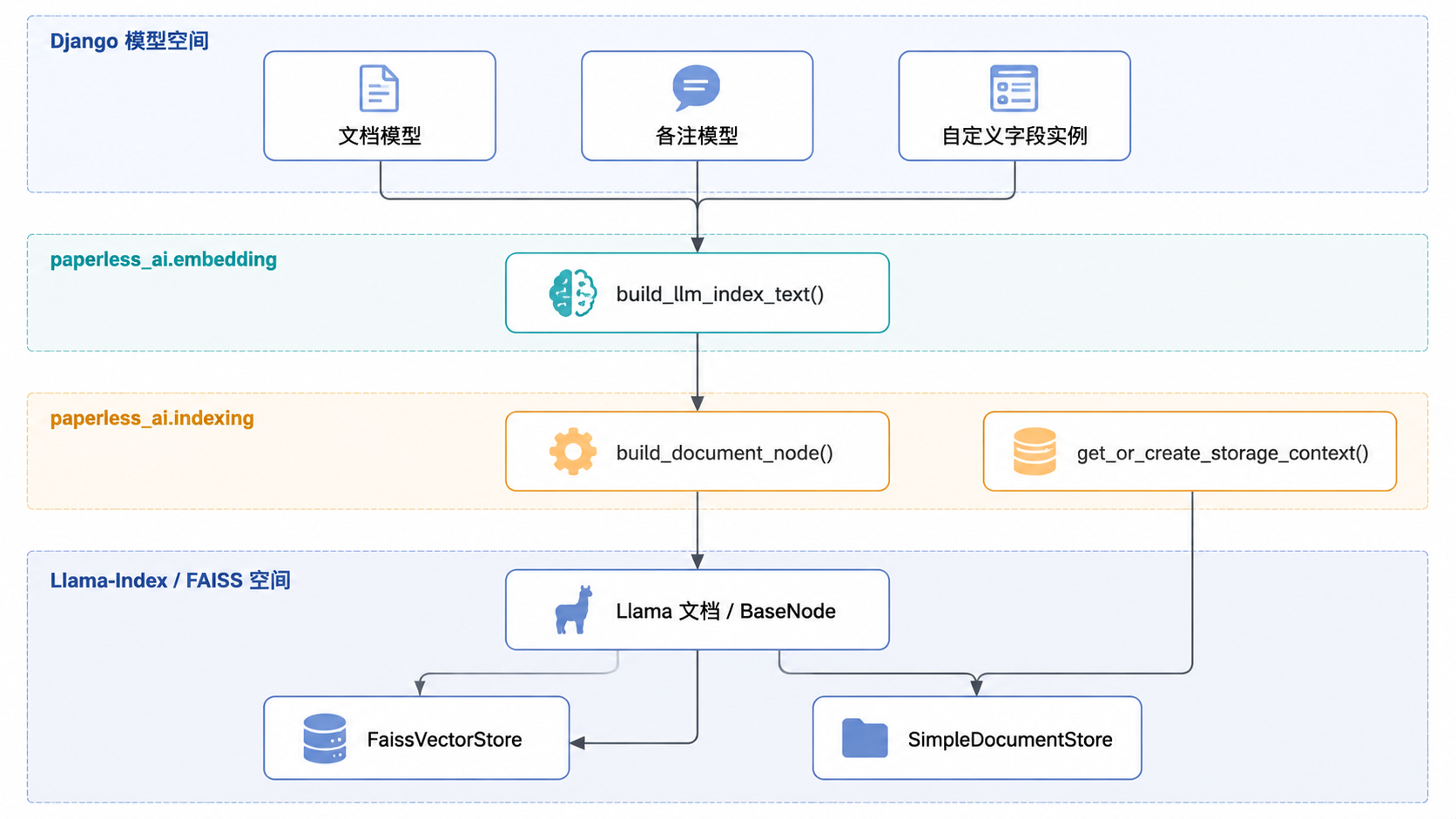
来源:src/paperless_ai/embedding.py:82-104,src/paperless_ai/indexing.py:91-115,src/paperless_ai/indexing.py:171-199
管理与任务
管理命令
document_llmindex 命令提供了用于索引管理的命令行接口。
python manage.py document_llmindex rebuild:删除现有索引并处理所有文档。python manage.py document_llmindex update:仅处理新增或修改的文档。
异步任务
索引更新通常通过 Celery 的 llmindex_index 任务来处理。系统使用 queue_llm_index_update_if_needed 来避免在更新任务正在运行或上次更新在 5 分钟内已完成时产生冗余任务。
逻辑流程:索引更新编排
下图展示了从管理命令到任务队列再到索引逻辑的控制流。
索引编排
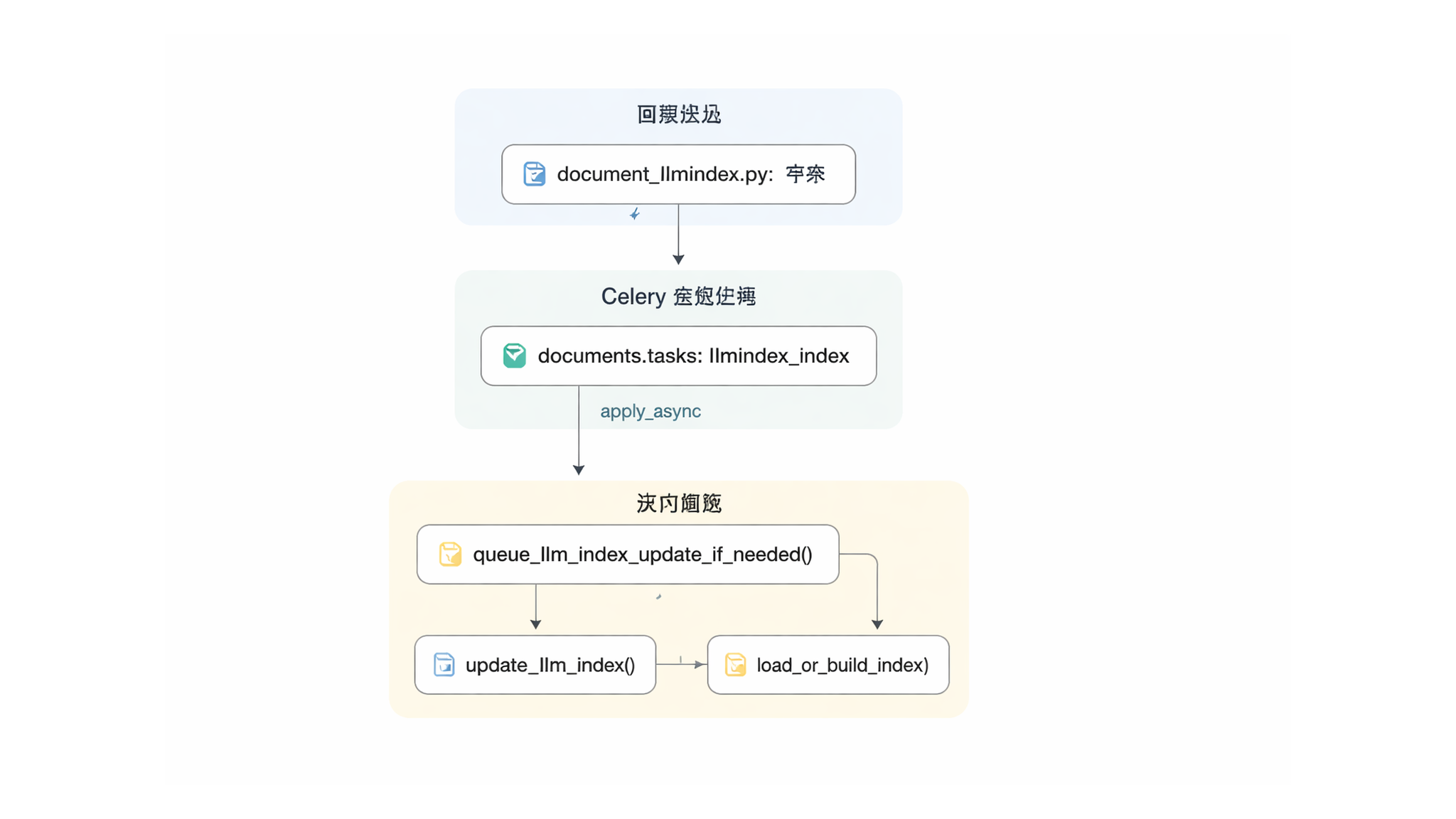
来源:src/documents/management/commands/document_llmindex.py:7-25,src/paperless_ai/indexing.py:26-50,src/paperless_ai/indexing.py:118-146