AI 驱动的文档建议
AI 驱动的文档建议
相关源文件
以下文件为本维基页面的生成提供了上下文:
src-ui/src/app/components/document-detail/document-detail.component.htmlsrc-ui/src/app/components/document-detail/document-detail.component.scsssrc-ui/src/app/components/document-detail/document-detail.component.spec.tssrc-ui/src/app/components/document-detail/document-detail.component.tssrc/documents/filters.pysrc/documents/serialisers.pysrc/documents/tests/test_api_custom_fields.pysrc/documents/tests/test_api_documents.pysrc/documents/tests/test_api_filter_by_custom_fields.pysrc/documents/views.pysrc/paperless/urls.py
Paperless-ngx 中的 AI 驱动文档建议系统可在用户审阅文档过程中提供智能元数据推荐。该系统通过利用大语言模型(LLM)和传统机器学习(ML)分类器,可以建议可能的通信方、标签和文档类型,并直接从文档内容中提取标题。
概述与架构
建议引擎通过一个专用的 API 操作来运行,该操作会聚合来自多个分类后端的结果。当用户打开文档详情视图时,前端会根据文档内容和现有元数据请求建议。
系统数据流
下图展示了从 Angular UI 到 Django 后端以及底层 AI/ML 实体的请求-响应流程。
图:建议请求管线
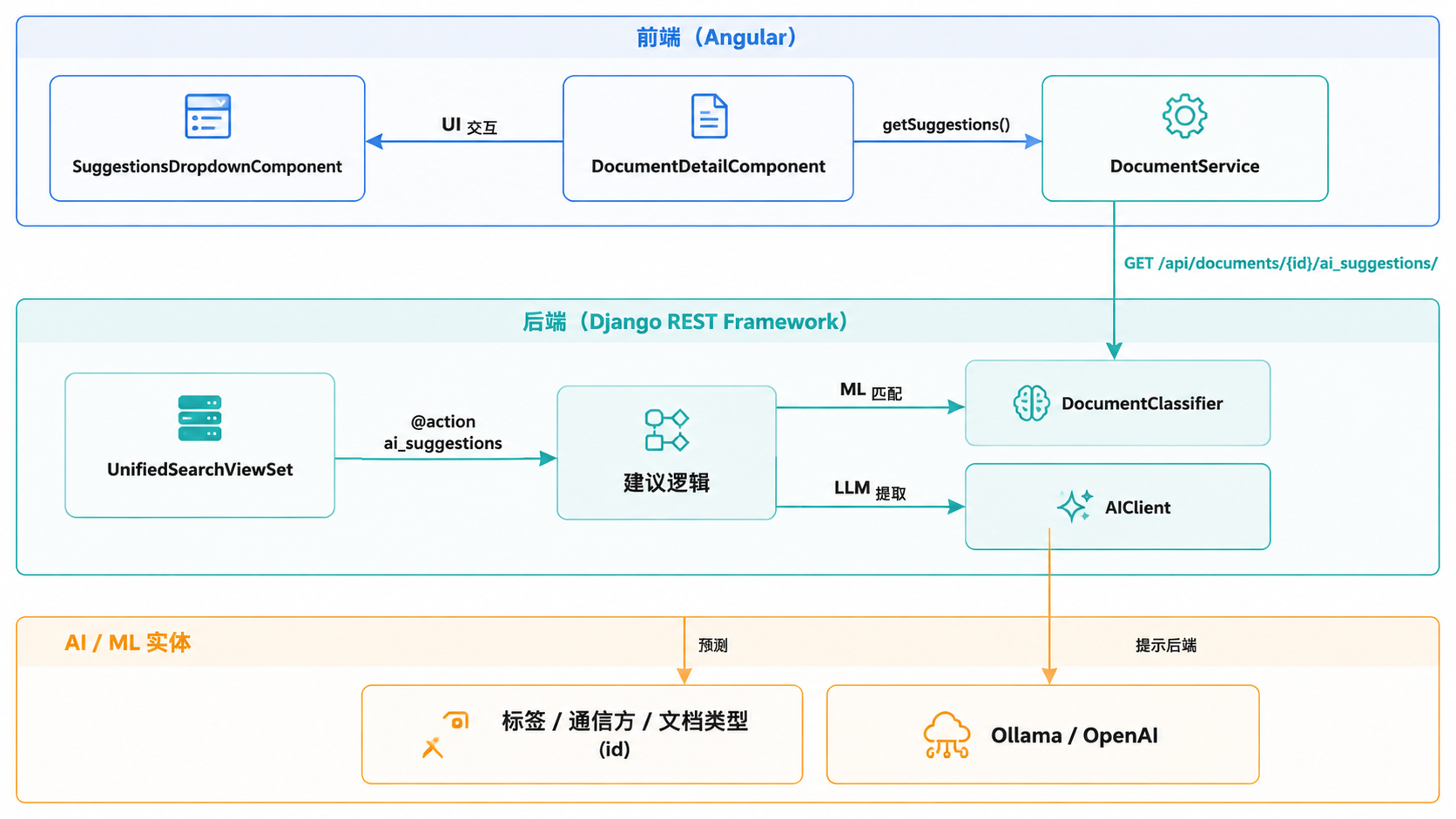
来源: src-ui/src/app/components/document-detail/document-detail.component.ts:1331-1340(组件结构) src/documents/views.py:88-106(操作装饰器和视图集) src/documents/classifier.py:120-120(分类器加载)
后端实现
核心逻辑位于 UnifiedSearchViewSet 中的 ai_suggestions 操作内。该端点负责协调标准分类器和基于 LLM 的提取。
ai_suggestions API 操作
触发时,后端会执行以下步骤:
- 缓存检查: 尝试使用
get_llm_suggestion_cache从缓存中检索先前计算过的建议src/documents/views.py:112-112。 - 分类器预测: 使用训练好的
DocumentClassifier根据文档内容预测元数据src/documents/views.py:120-120。 - LLM 提取: 如果配置了 AI 后端,则调用
AIClient执行"文档信息提取"。 - 结果聚合: 将预测结果和提取结果合并为统一的模式。
数据结构
系统使用特定的模式来确保 LLM 输出与内部数据库之间的一致性。
| 实体 | 类 / 模式 | 用途 |
|---|---|---|
| 建议集 | DocumentSuggestions | 前端接口,用于保存建议 ID 的数组。 |
| LLM 输出 | DocumentClassifierSchema | 类似 Pydantic 的模式,用于强制 LLM 返回结构化的 JSON。 |
来源: src/documents/views.py:88-106(API 操作定义) src-ui/src/app/data/document-suggestions.ts:1-10(前端数据模型)
基于 LLM 的提取
与依赖历史模式的标准分类器不同,LLM 后端(Ollama 或兼容 OpenAI 的接口)会"阅读"文档文本来提取特定字段。
提取逻辑
系统会将文档的 content 传递给 LLM,并附带指令以识别:
- 标题: 文档的简洁摘要。
- 日期: 文档的创建或签发日期。
- 通信方: 发件人或组织。
- 标签: 相关分类。
图:LLM 实体映射
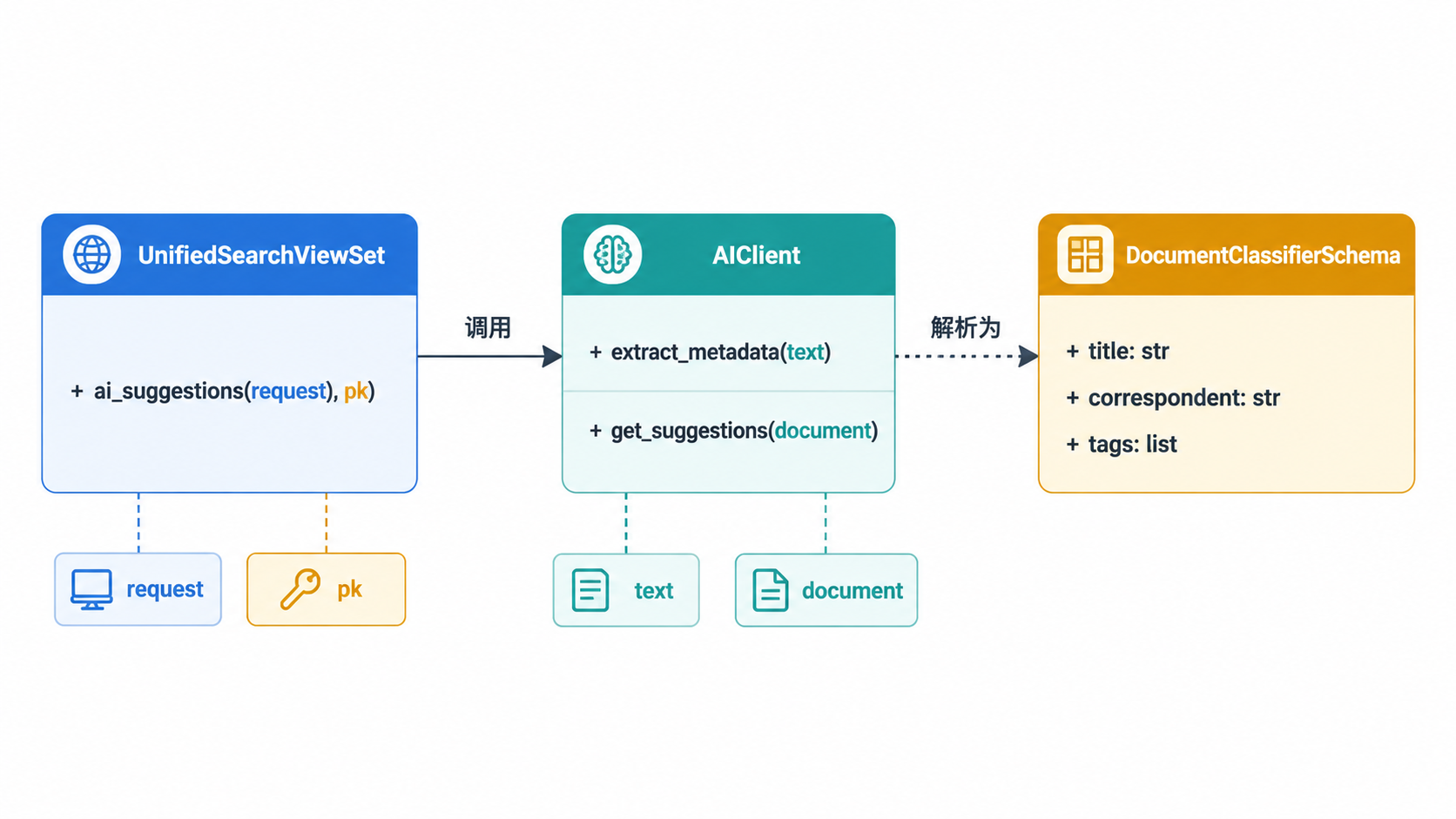
来源: src/documents/views.py:88-106(视图集交互) src/paperless_ai/client.py(提取逻辑的实现)
前端集成
前端在 DocumentDetailComponent 中展示建议。
UI 组件
- SuggestionsDropdownComponent: 位于详情视图的工具栏中
src-ui/src/app/components/document-detail/document-detail.component.html:131-141。在获取建议时会显示加载旋转图标。 - 视觉指示器: 建议会在元数据字段(通信方、文档类型、标签)中高亮显示。用户可以点击建议立即应用。
交互逻辑
在 DocumentDetailComponent 中,当用户点击建议按钮时会调用 getSuggestions() 方法:
- 它会将
suggestionsLoading设置为truesrc-ui/src/app/components/document-detail/document-detail.component.ts:1331-1340。 - 它会调用
this.documentService.getSuggestions(id)src-ui/src/app/services/rest/document.service.ts。 - 收到响应后,它会更新
suggestions可观察对象,SuggestionsDropdownComponent会订阅该对象。
来源: src-ui/src/app/components/document-detail/document-detail.component.ts:1331-1340(组件逻辑) src-ui/src/app/components/document-detail/document-detail.component.html:131-141(模板集成)
缓存与性能
为了最小化 LLM API 的成本和延迟,建议会被缓存。
- 缓存键: 建议按文档 ID 进行缓存。
- 失效策略: 当文档内容发生变化或用户手动请求重新扫描时,缓存会被刷新。
- 函数:
set_llm_suggestions_cache和get_llm_suggestion_cache在 Django 缓存后端中管理这些条目src/documents/views.py:112-117。
来源:
src/documents/views.py:112-119(缓存工具导入)