文字识别与文本抽取
OCR 与文本提取
相关源文件
以下文件为本维基页面的生成提供了上下文:
paperless.conf.examplesrc/documents/__init__.pysrc/documents/admin.pysrc/documents/apps.pysrc/documents/checks.pysrc/documents/consumer.pysrc/documents/file_handling.pysrc/documents/management/commands/document_archiver.pysrc/documents/management/commands/document_index.pysrc/documents/management/commands/document_renamer.pysrc/documents/management/commands/document_sanity_checker.pysrc/documents/management/commands/document_thumbnails.pysrc/documents/matching.pysrc/documents/models.pysrc/documents/parsers.pysrc/documents/signals/handlers.pysrc/documents/tests/factories.pysrc/documents/tests/test_admin.pysrc/documents/tests/test_checks.pysrc/documents/tests/test_consumer.pysrc/documents/tests/test_document_model.pysrc/documents/tests/test_file_handling.pysrc/documents/tests/test_management_thumbnails.pysrc/documents/tests/test_matchables.pysrc/documents/tests/test_models.pysrc/documents/tests/test_parsers.pysrc/documents/tests/test_task_signals.py
本文档说明了 Paperless-ngx 如何通过光学字符识别(OCR)及其他文本提取方法从文档中提取文本。文本提取是文档处理管线的核心环节,它使文档内容可被搜索,并支持自动分类。
概述
Paperless-ngx 根据文档类型采用不同的文本提取方法。系统会根据文件的 MIME 类型选择对应的解析器。OCR 的主要引擎是 OCRmyPDF,它底层依赖 Tesseract。对于 Office 文件等非图像文档,Paperless-ngx 可以选用 Apache Tika 和 Gotenberg。
文本提取决策流程
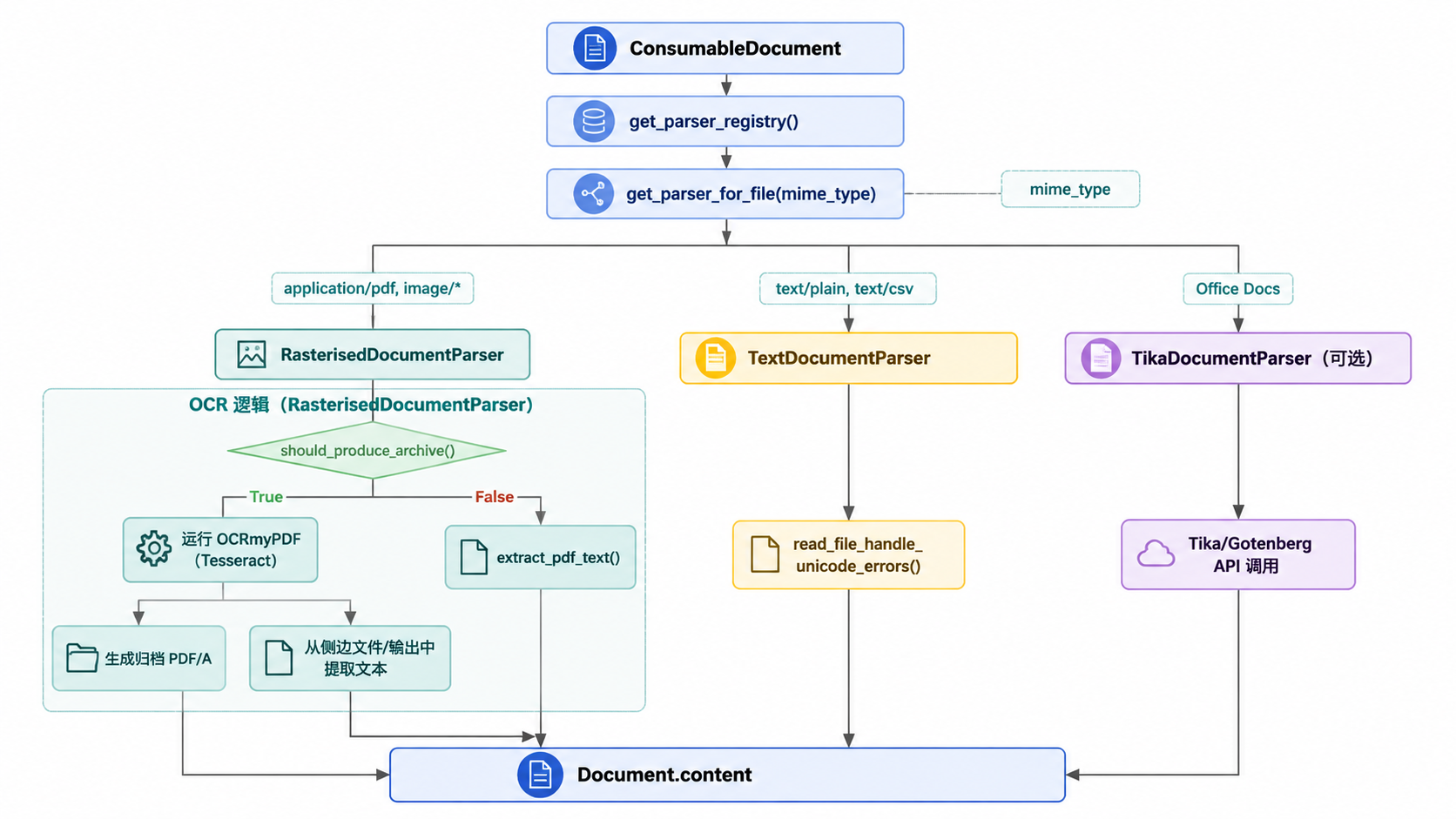
来源:src/documents/consumer.py:124-188, src/documents/parsers.py:25-30, src/documents/consumer.py:59-63。
解析器选择与 MIME 类型
get_parser_registry() 函数返回一个单例注册表,用于将 MIME 类型映射到解析器类。消费者使用该注册表来实例化正确的 DocumentParser 子类。
| MIME 类型 | 解析器类 | 主要工具 |
|---|---|---|
application/pdf | RasterisedDocumentParser | OCRmyPDF / pdftotext |
image/*(png、jpeg、webp) | RasterisedDocumentParser | OCRmyPDF(Tesseract) |
text/plain、text/csv | TextDocumentParser | Python open() |
application/vnd.openxmlformats-* | TikaDocumentParser | Apache Tika / Gotenberg |
来源:src/documents/parsers.py:32-44, src/documents/tests/test_consumer.py:40-58, src/paperless.conf.example:85-87。
OCR 流程(OCRmyPDF 集成)
对于图像和 PDF,RasterisedDocumentParser 会调用 OCRmyPDF。是否执行 OCR 或仅提取现有文本,由 should_produce_archive 和 PAPERLESS_OCR_MODE 设置决定。
归档生成逻辑
should_produce_archive 函数决定是否应创建 PDF/A 版本:
- 始终:如果
PAPERLESS_OCR_MODE设置为always。 - 自动:对于图像或
is_tagged_pdf为 false 的 PDF,或者extract_pdf_text返回的文本长度小于PDF_TEXT_MIN_LENGTH(51 个字符)的 PDF。 - 从不:如果显式禁用或解析器无法生成归档。
来源:src/documents/consumer.py:124-188, src/documents/consumer.py:60-61。
OCR 配置
paperless.conf 中的设置会映射为 OCRmyPDF 的参数:
PAPERLESS_OCR_LANGUAGE:作为-l参数传递。PAPERLESS_OCR_DESKEW:作为--deskew参数传递。PAPERLESS_OCR_USER_ARGS:用于额外 CLI 标志的 JSON 字符串。PAPERLESS_OCR_PAGES:限制 OCR 仅处理特定页面。
来源:src/paperless.conf.example:40-52, src/documents/consumer.py:55-56。
缩略图创建
每个被消费的文档都需要生成缩略图。DocumentParser.get_thumbnail 方法负责此任务。
- PDF:使用
make_thumbnail_from_pdf,该方法调用 ImageMagick(convert)。 - Ghostscript 回退:如果 ImageMagick 失败(通常由于安全策略),
make_thumbnail_from_pdf_gs_fallback使用gs提取 PNG,然后将其转换为 WebP。 - 默认:如果所有方法都失败,
get_default_thumbnail()返回一个通用文档图标。
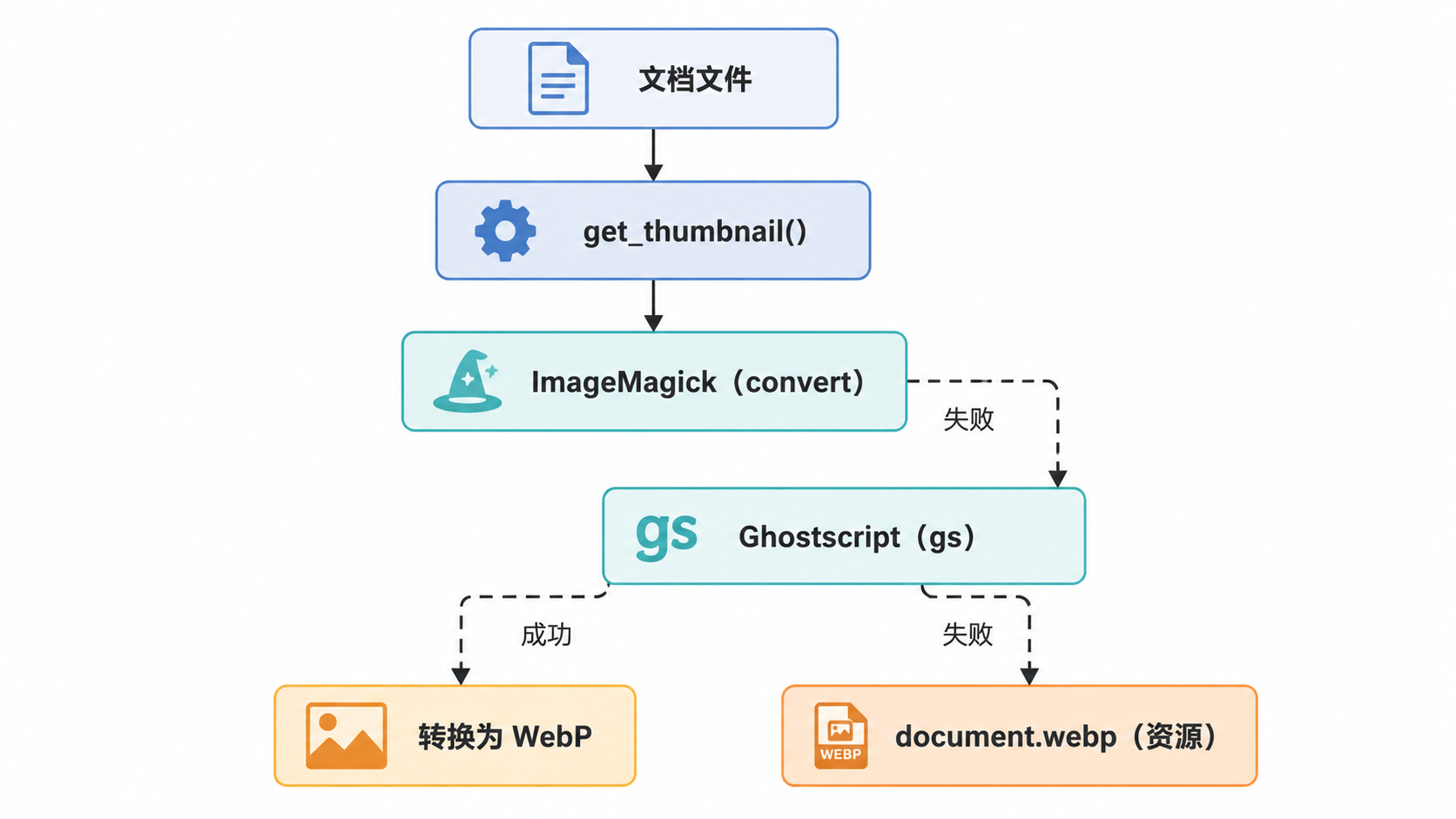
来源:src/documents/parsers.py:174-198, src/documents/parsers.py:130-172, src/documents/parsers.py:123-127。
Office 文档(Tika 和 Gotenberg)
当 PAPERLESS_TIKA_ENABLED 为 true 时,Paperless-ngx 会使用两个外部服务:
- Gotenberg:将 Office 格式(doc、docx、xls 等)转换为 PDF。
- Apache Tika:从这些格式中提取文本和元数据。
消费者首先将文件发送给 Gotenberg 以生成"渲染后"的 PDF,然后该 PDF 会经过标准的 OCR/提取管线处理,以确保存在一致的 PDF/A 归档。
来源:src/paperless.conf.example:85-87。
管理命令
Paperless-ngx 提供了管理命令,用于管理现有文档的 OCR 和缩略图。
document_archiver
该命令遍历文档并重新生成其 PDF/A 归档文件。在更改 OCR 设置(例如更改 OCR 语言)后,该命令非常有用。
- 参数:
-f / --overwrite:即使归档已存在,也重新创建。-d / --document [ID]:仅对单个特定文档执行操作。
来源:src/documents/management/commands/document_archiver.py:12-45, src/documents/management/commands/document_archiver.py:57-68。
document_thumbnails
重新生成文档的缩略图。通常在更改缩略图质量设置或缩略图损坏时使用。
- 实现:使用
process_parallel更新Document模型上的thumbnail字段。
来源:src/documents/management/commands/document_thumbnails.py:1-20。
数据流:代码实体空间
下图将高级 OCR 概念映射到代码库中的具体类和函数。
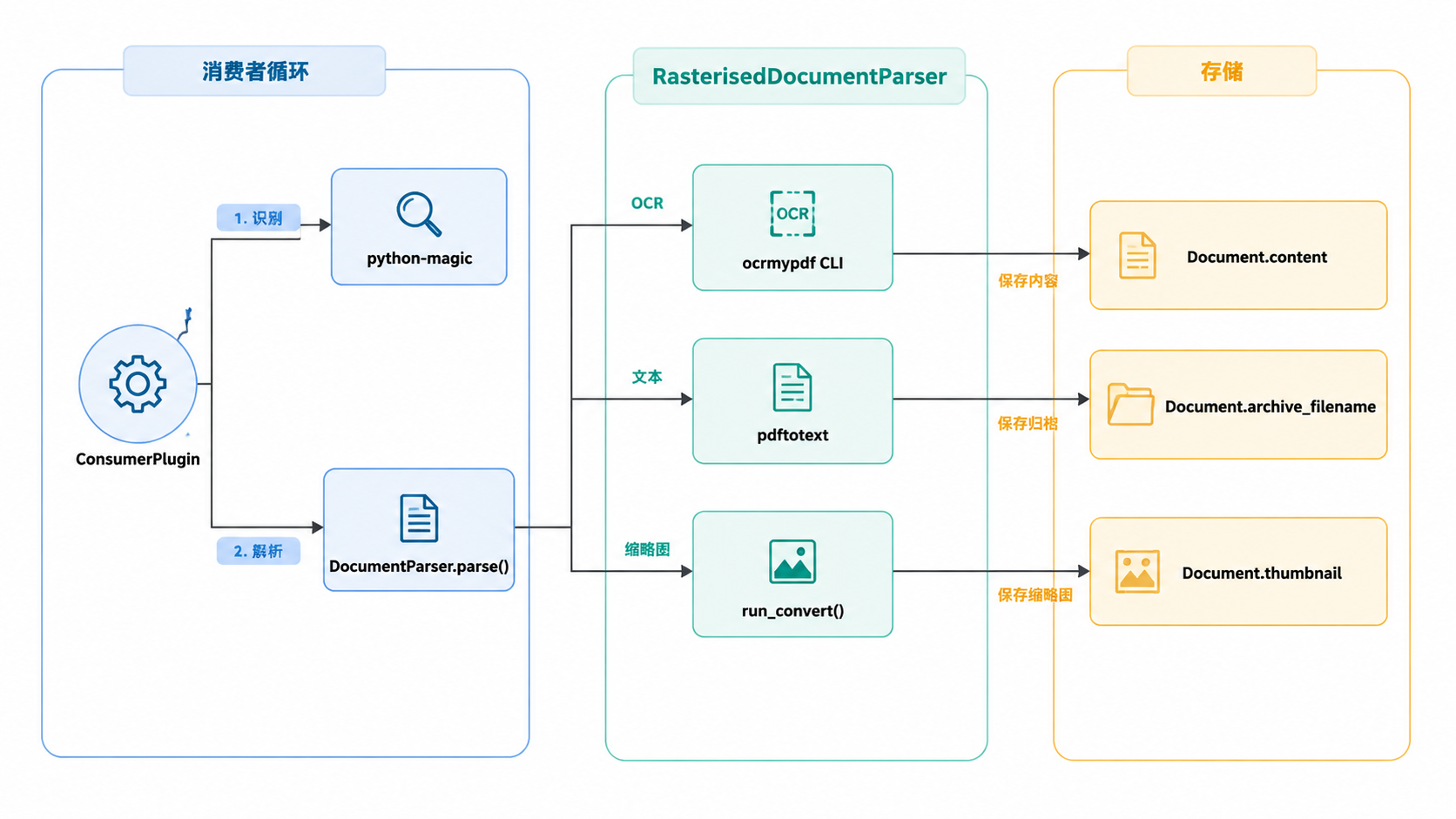
来源:src/documents/consumer.py:11-19, src/documents/parsers.py:71-121, src/documents/models.py:157-230。
处理元数据和日期
在提取过程中,系统还会尝试在文本中查找"创建"日期。
- 逻辑:使用
get_date_parser()扫描内容,查找由PAPERLESS_FILENAME_DATE_ORDER定义的模式。 - 工作流:如果在文本中找到日期,并且文件元数据未提供日期,则提取的日期会被分配给
Document.created。
来源:src/documents/consumer.py:43-45, src/documents/models.py:234-250。