文档分类
文档分类
相关源文件
本章引用的主要源码文件:
paperless.conf.examplesrc/documents/__init__.pysrc/documents/admin.pysrc/documents/apps.pysrc/documents/checks.pysrc/documents/classifier.pysrc/documents/consumer.pysrc/documents/file_handling.pysrc/documents/management/commands/document_create_classifier.pysrc/documents/management/commands/document_retagger.pysrc/documents/matching.pysrc/documents/models.pysrc/documents/parsers.pysrc/documents/signals/handlers.pysrc/documents/tests/factories.pysrc/documents/tests/test_admin.pysrc/documents/tests/test_checks.pysrc/documents/tests/test_classifier.pysrc/documents/tests/test_consumer.pysrc/documents/tests/test_document_model.pysrc/documents/tests/test_file_handling.pysrc/documents/tests/test_management_retagger.pysrc/documents/tests/test_matchables.pysrc/documents/tests/test_models.pysrc/documents/tests/test_parsers.pysrc/documents/tests/test_task_signals.py
本文详细介绍了 Paperless-ngx 中的文档分类系统,该系统会根据文档内容自动为其分配元数据。系统主要采用两种方法:基于规则匹配(使用多种算法)和基于机器学习(通过训练模型进行自动分类)。
概述
文档内容通过 OCR 提取后(参见 4.2 OCR 与文本提取),系统会进行文档分类。系统分析文档文本以决定应应用哪些元数据。支持自动分配的元数据实体包括通信方(Correspondent)、文档类型(DocumentType)、标签(Tag)和存储路径(StoragePath)。这些模型都继承自 MatchingModel src/documents/models.py:46-95。
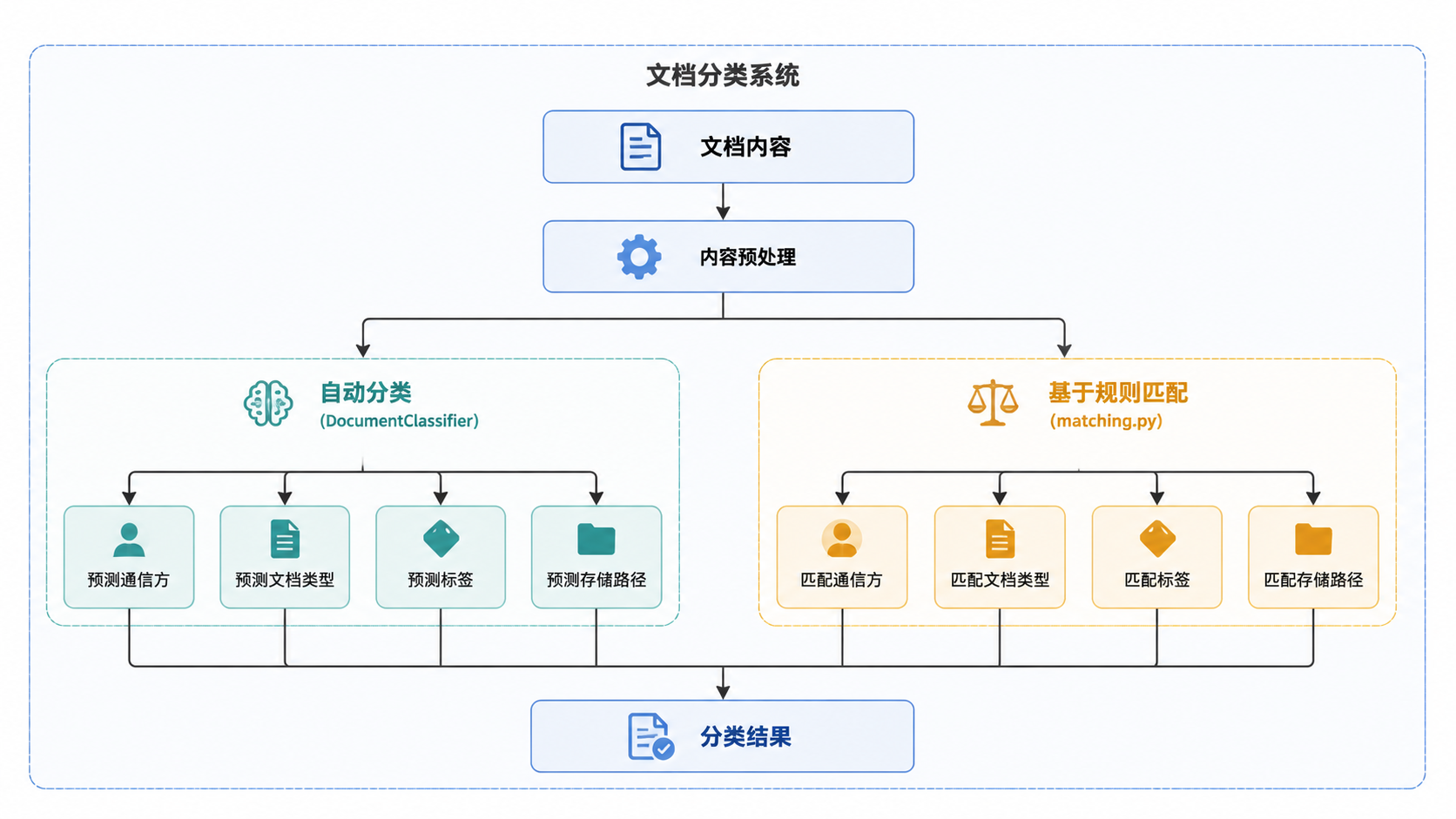
来源:src/documents/classifier.py:97-134,src/documents/matching.py:47-167
匹配算法
Paperless-ngx 支持多种在 MatchingModel 抽象类中定义的匹配算法 src/documents/models.py:46-63。每个元数据对象都可以配置特定的算法和匹配字符串。
| 算法 | 代码常量 | 描述 |
|---|---|---|
| 无 | MATCH_NONE | 不执行自动匹配。 |
| 任意词 | MATCH_ANY | 如果匹配字符串中任意一个以空格分隔的词出现在文档中,则匹配成功。 |
| 所有词 | MATCH_ALL | 仅当匹配字符串中所有以空格分隔的词都出现在文档中时,才匹配成功。 |
| 精确匹配 | MATCH_LITERAL | 匹配精确字符串(包括空格)。 |
| 正则表达式 | MATCH_REGEX | 使用正则表达式模式进行匹配。 |
| 模糊词 | MATCH_FUZZY | 使用模糊匹配查找近似词匹配。 |
| 自动 | MATCH_AUTO | 使用训练好的 DocumentClassifier 机器学习模型。 |
这些算法的实现位于 src/documents/matching.py 的 matches 函数中 src/documents/matching.py:169-236。
来源:src/documents/models.py:46-73,src/documents/matching.py:169-236
机器学习分类
DocumentClassifier 类负责管理机器学习的整个生命周期。它使用 scikit-learn 的 MLPClassifier(多层感知器)进行分类,并使用 CountVectorizer 进行文本特征提取 src/documents/classifier.py:97-128。
内容预处理
在训练或预测之前,文档内容会经过预处理以规范化输入 src/documents/classifier.py:359-419。
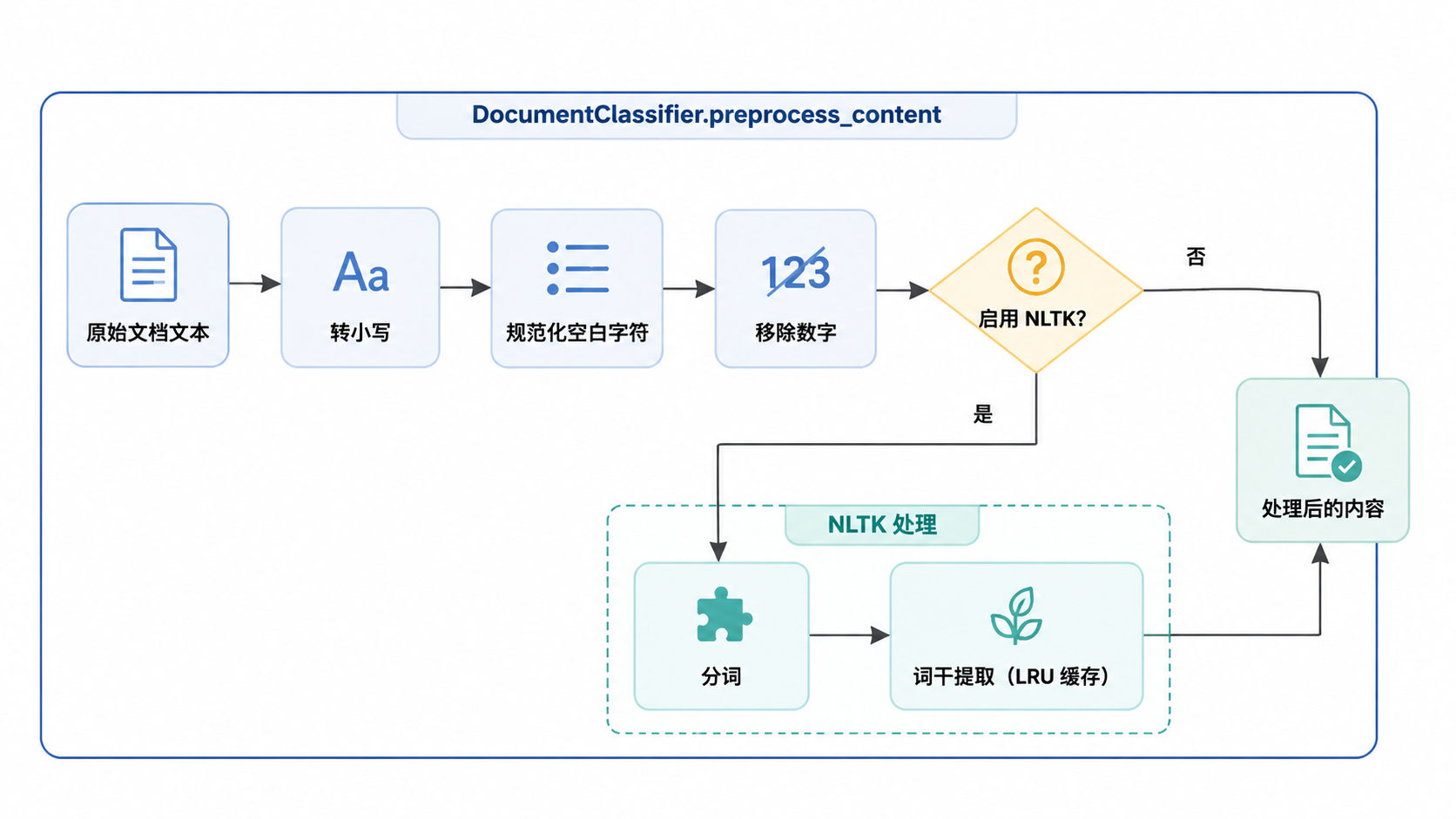
如果设置了 NLTK_ENABLED,系统会执行词干提取,并使用 StoredLRUCache 进行缓存,以最小化查找延迟 src/documents/classifier.py:123-127。
来源:src/documents/classifier.py:359-419,src/documents/classifier.py:123-127
模型训练
分类器通过 document_create_classifier 管理命令进行训练。它会选择不在收件箱中的文档,并使用它们当前的元数据作为标签 src/documents/classifier.py:167-357。
- 数据收集:获取文档及其关联的标签、通信方等。
- 向量化:将内容转换为文档-词项矩阵。
- 训练:分别为
tags、correspondent、document_type和storage_path训练独立的分类器。 - 持久化:模型被序列化(pickle),使用
settings.SECRET_KEY进行 HMAC 签名,并保存到settings.MODEL_FILEsrc/documents/classifier.py:136-141。
来源:src/documents/classifier.py:167-357,src/documents/classifier.py:136-141
与处理管线的集成
分类是在消费过程中通过信号触发的。src/documents/signals/handlers.py 中的关键处理器负责管理元数据的分配。
元数据分配逻辑
set_correspondent、set_document_type 和 set_tags 等函数协调匹配过程 src/documents/signals/handlers.py:93-187。
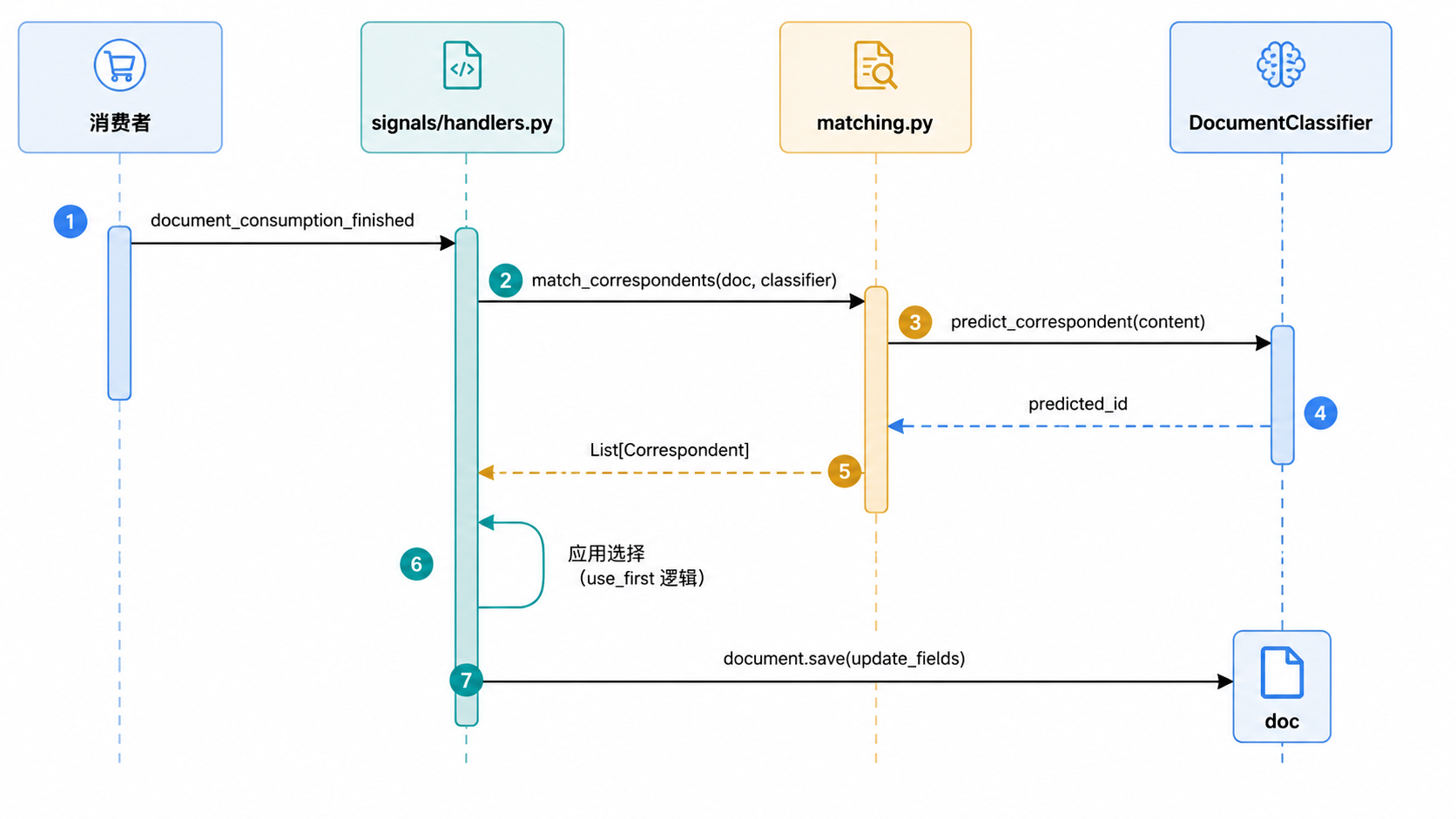
- 基于规则 + 自动:
matching.py中的匹配函数会结合基于规则算法和机器学习预测的结果src/documents/matching.py:47-76。 - 歧义处理:如果多个通信方或类型匹配,系统通常会避免分配,除非启用了
use_firstsrc/documents/signals/handlers.py:128-141。
来源:src/documents/signals/handlers.py:93-187,src/documents/matching.py:47-134
管理命令
document_retagger
document_retagger 命令允许用户将分类逻辑追溯应用到现有文档 src/documents/management/commands/document_retagger.py:175-210。
- 选项:支持
--overwrite以替换现有元数据,以及--suggest以预览更改而不保存src/documents/management/commands/document_retagger.py:188-215。 - 统计信息:提供实时更新的更改表(添加/删除的标签、设置的通信方)
src/documents/management/commands/document_retagger.py:71-98。
document_create_classifier
此命令强制重新训练机器学习模型。它通常通过计划任务运行,但也可以在元数据发生重大更改后手动调用以刷新模型。
来源:src/documents/management/commands/document_retagger.py:175-215,src/documents/classifier.py:167-170
实现细节
模型完整性
系统在加载时会检查模型的兼容性。如果 FORMAT_VERSION 不匹配或 HMAC 签名无效,则分类器被视为已损坏,并会取消链接文件以触发重新训练 src/documents/classifier.py:143-178。
收件箱标签
新消费的文档会通过 add_inbox_tags 处理器自动分配“收件箱”标签,前提是该标签的 is_inbox_tag 属性为 true src/documents/signals/handlers.py:80-91。
来源:src/documents/classifier.py:143-178,src/documents/signals/handlers.py:80-91