后端架构
后端架构
相关源文件
本章引用的主要源码文件:
paperless.conf.examplesrc/documents/admin.pysrc/documents/apps.pysrc/documents/consumer.pysrc/documents/file_handling.pysrc/documents/filters.pysrc/documents/models.pysrc/documents/parsers.pysrc/documents/serialisers.pysrc/documents/signals/handlers.pysrc/documents/tests/test_api_app_config.pysrc/documents/tests/test_api_custom_fields.pysrc/documents/tests/test_api_documents.pysrc/documents/tests/test_api_filter_by_custom_fields.pysrc/documents/tests/test_api_permissions.pysrc/documents/tests/test_consumer.pysrc/documents/tests/test_file_handling.pysrc/documents/views.pysrc/paperless/config.pysrc/paperless/serialisers.pysrc/paperless/urls.pysrc/paperless/validators.pysrc/paperless/views.py
本文档全面概述了 Paperless-ngx 中基于 Django 的后端架构。后端作为文档管理系统的基础,提供了文档存储、检索、处理和自动化的 API。有关前端架构的信息,请参见前端架构。
后端组件概览
Paperless-ngx 的后端基于 Django 和 Django REST Framework 构建。它采用分层架构,在数据模型、API 端点、文档处理和后台任务之间实现了清晰的关注点分离。
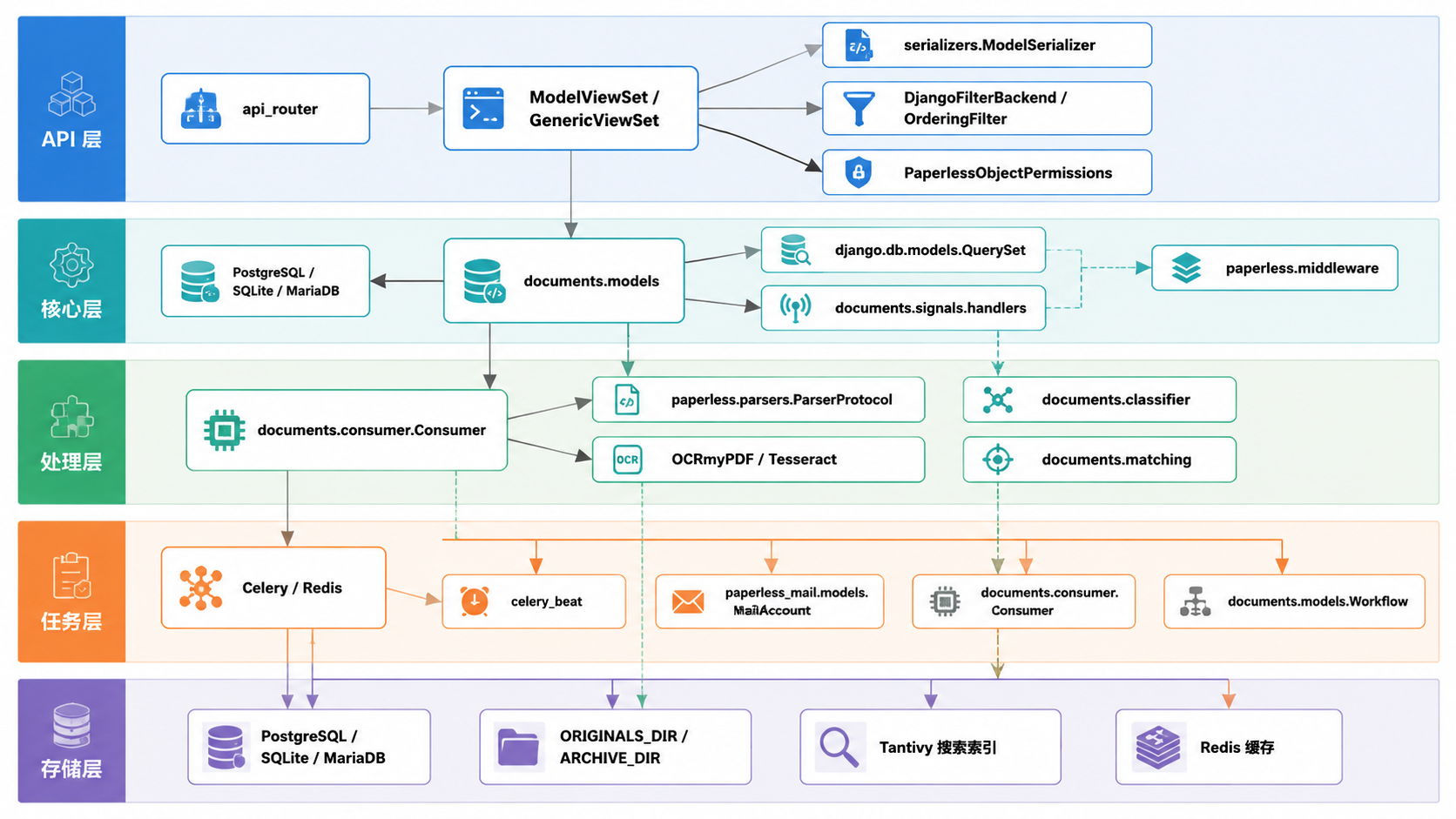
来源: src/paperless/urls.py:70-91 src/documents/views.py:523-558 src/documents/consumer.py:67-88 src/documents/models.py:157-234
核心数据模型
后端围绕一组 Django 模型构建,这些模型代表文档及其相关实体。Document 模型是核心实体,与各种支持模型存在关联关系。详细信息请参见文档数据模型。
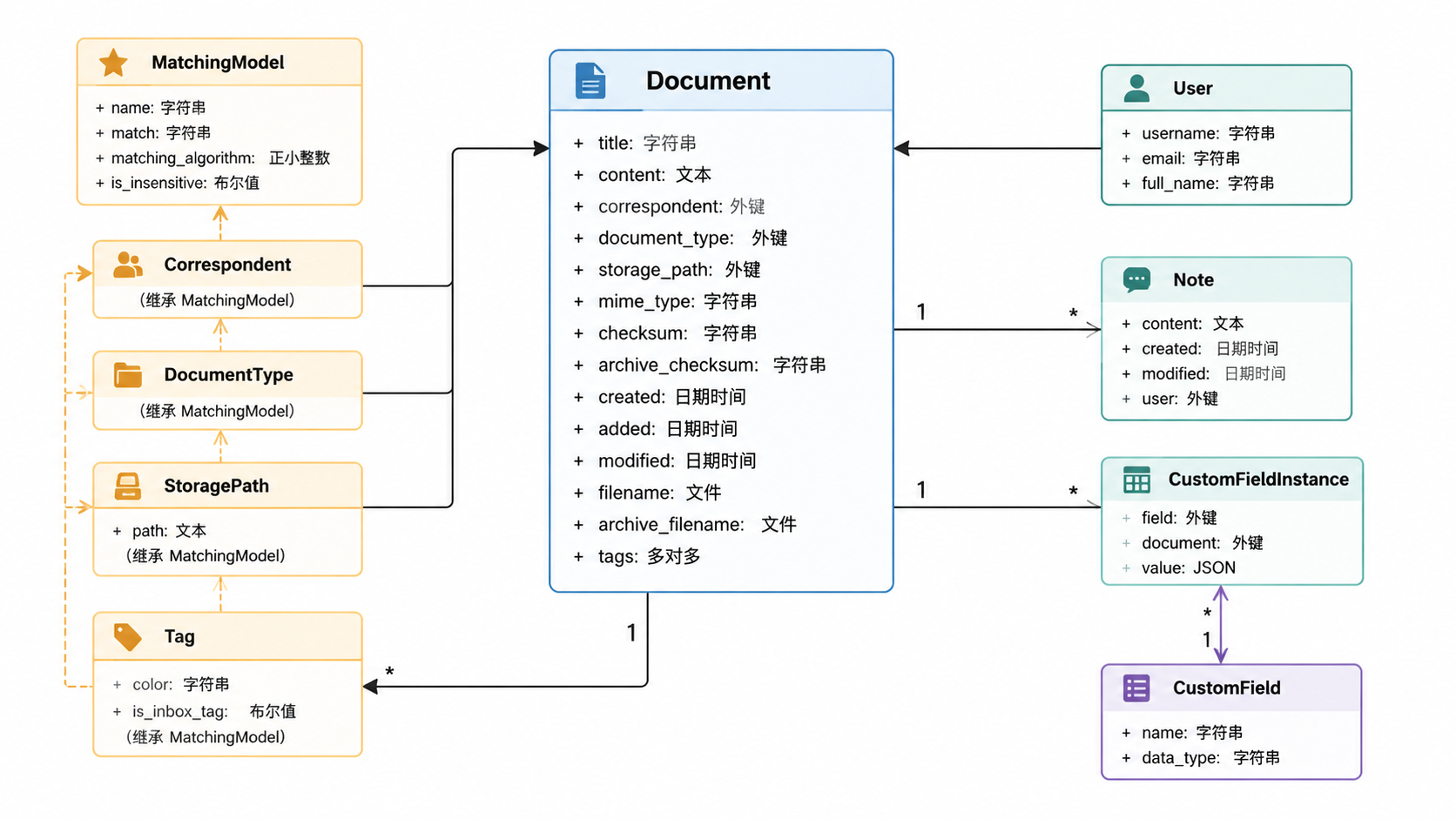
来源: src/documents/models.py:46-95 src/documents/models.py:157-375 src/documents/models.py:102-140
MatchingModel 基类
许多核心模型继承自 MatchingModel,该类提供了根据文档内容进行匹配的功能。它支持在 src/documents/models.py:47-63 中定义的多种匹配算法。
MATCH_NONE(0):不进行匹配。MATCH_ANY(1):匹配任意单词。MATCH_ALL(2):匹配所有单词。MATCH_LITERAL(3):精确匹配。MATCH_REGEX(4):正则表达式匹配。MATCH_FUZZY(5):模糊单词匹配。MATCH_AUTO(6):通过DocumentClassifier自动匹配。
来源: src/documents/models.py:46-73 src/documents/matching.py:1-20
文档存储
文档存储在文件系统中,元数据保存在数据库中。Document 模型通过 SoftDeleteModel src/documents/models.py:157 实现软删除。
- 原始文件:未经修改的原始文档,存储在
ORIGINALS_DIR目录中。 - 归档文件:用于查看的优化版本(通常为 PDF/A),存储在
ARCHIVE_DIR目录中。 - 缩略图:用于预览的 WebP 格式缩略图,存储在
THUMBNAIL_DIR目录中。
来源: src/documents/models.py:305-370 src/documents/file_handling.py:19-40
API 层
后端使用 Django REST Framework 构建 REST API,并通过 drf-spectacular 进行文档化。详细信息请参见API 和视图集。
API 结构
API 以 /api/ 前缀进行组织。src/paperless/urls.py:70-91 中的 DefaultRouter 定义了主要资源端点。
| 端点 | 视图集/视图 | 描述 |
|---|---|---|
/api/documents/ | UnifiedSearchViewSet | 列出、搜索和管理文档。 |
/api/tags/ | TagViewSet | 文档标签的增删改查。 |
/api/correspondents/ | CorrespondentViewSet | 文档通信方的增删改查。 |
/api/tasks/ | TasksViewSet | 监控后台任务状态。 |
/api/workflows/ | WorkflowViewSet | 管理自动化工作流。 |
/api/search/ | GlobalSearchView | 跨实体的全局全文搜索。 |
来源: src/paperless/urls.py:70-166 src/documents/views.py:523-614
过滤和权限
API 通过 Django Filter 后端和对象级安全机制支持高级过滤。详细信息请参见权限系统。
DocumentFilterSet:按标签、日期范围、自定义字段和内容过滤文档src/documents/filters.py:134。ObjectOwnedOrGrantedPermissionsFilter:确保用户只能看到自己拥有或通过django-guardian被授予访问权限的文档src/documents/filters.py:137。
来源: src/documents/filters.py:68-143 src/documents/views.py:535-566
文档处理管线
文档处理管线负责消费、处理、存储和索引文档。详细信息请参见文档处理管线。
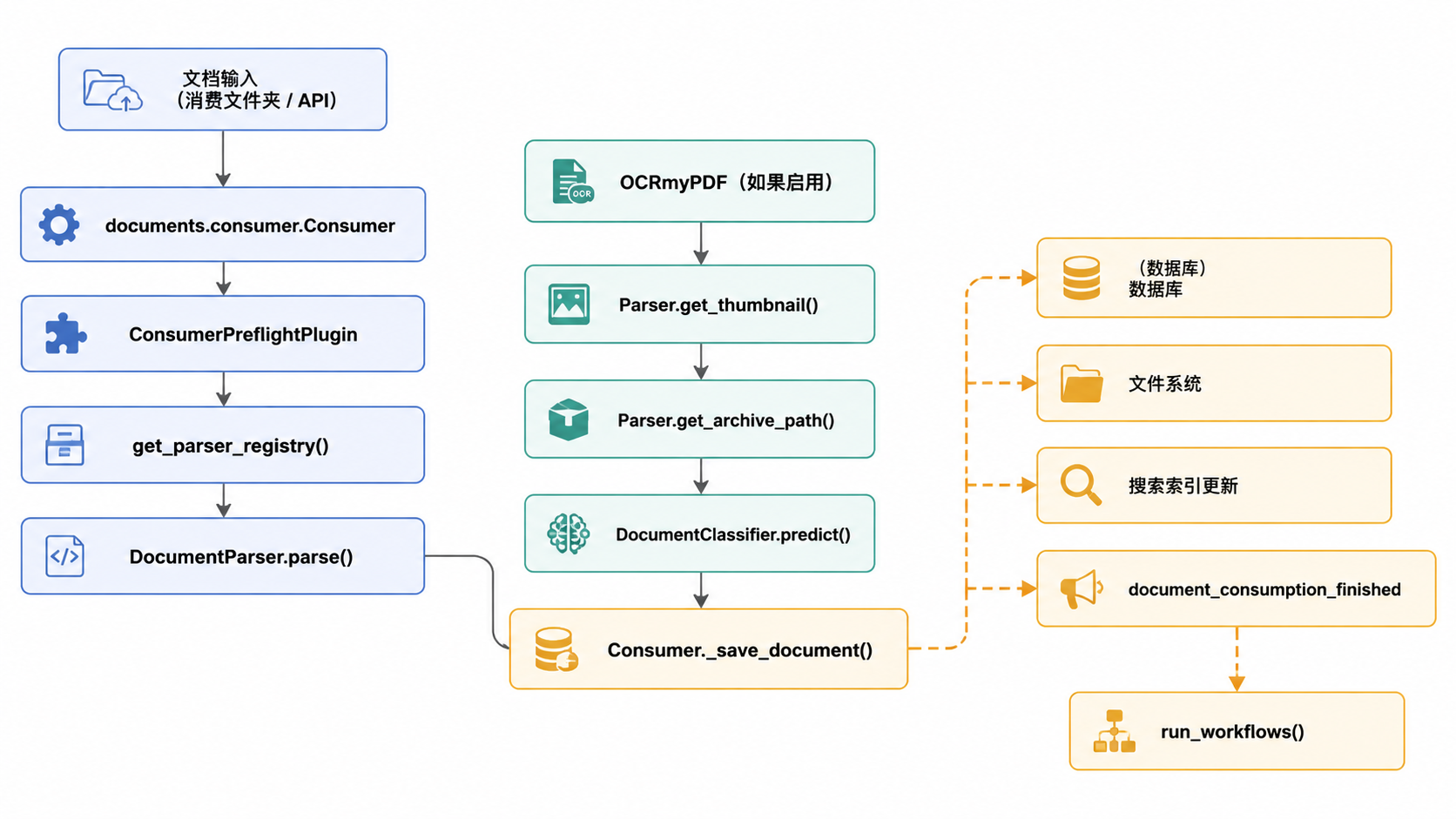
来源: src/documents/consumer.py:356-633 src/documents/signals/handlers.py:49-66
消费者和解析器
Consumer 类 src/documents/consumer.py:19-20 负责编排整个处理过程。它使用解析器注册表 src/paperless/parsers/registry.py 来处理不同的文件格式:
PDFParser:用于 PDF 文档。TesseractParser:用于需要 OCR 处理的图像。TextDocumentParser:用于纯文本文件。
来源: src/documents/consumer.py:124-184 src/documents/parsers.py:205-210
搜索和索引
Paperless-ngx 使用基于 Tantivy 的全文检索引擎,以实现高性能的索引和查询。详细信息请参见搜索和索引。
- 索引:文档在消费或更新时通过信号进行索引
src/documents/signals/handlers.py。 - 模式:搜索模式包括文档内容、元数据(标签、通信方)和自定义字段
src/documents/index.py。 - 过滤:搜索结果会根据用户权限自动过滤,使用
ObjectOwnedOrGrantedPermissionsFiltersrc/documents/filters.py:137。
来源: src/documents/views.py:49-105 src/documents/filters.py:58-60
任务管理
后台任务使用 Celery 进行管理,以 Redis 作为消息代理。
consume_file:处理新文档的主要任务。train_classifier:定期训练文档分类的机器学习模型。sanity_check:检查数据库与文件系统之间的一致性src/documents/tasks.py:32。mail_fetcher:定期从配置的 IMAP 账户获取邮件。
来源: src/paperless/settings.py:839-872 src/documents/signals/handlers.py:12-18
配置
系统通过环境变量或 paperless.conf 文件进行配置。关键设置包括:
PAPERLESS_REDIS:Redis 消息代理和缓存的连接字符串paperless.conf.example:6。PAPERLESS_DBHOST:数据库主机paperless.conf.example:7。PAPERLESS_FILENAME_FORMAT:存储中文件命名的模板paperless.conf.example:21。PAPERLESS_OCR_LANGUAGE:OCR 的默认语言paperless.conf.example:40。
来源:
paperless.conf.example:1-95src/paperless/config.py:1-50