文档处理管线
文档处理管线
相关源文件
本章引用的主要源码文件:
paperless.conf.examplesrc/documents/admin.pysrc/documents/apps.pysrc/documents/consumer.pysrc/documents/file_handling.pysrc/documents/models.pysrc/documents/parsers.pysrc/documents/sanity_checker.pysrc/documents/signals/handlers.pysrc/documents/tasks.pysrc/documents/tests/conftest.pysrc/documents/tests/test_consumer.pysrc/documents/tests/test_file_handling.pysrc/documents/tests/test_management.pysrc/documents/tests/test_sanity_check.pysrc/documents/tests/test_tasks.pysrc/documents/utils.py
本文档详细介绍了文档在 Paperless-ngx 系统中从入库、处理到存储的端到端流程。它重点描述了处理管线的内部工作机制,从文档进入系统的那一刻起,直到它被完全索引并可搜索为止。
关于文档消费方式(文档如何进入系统)的信息,请参阅文档消费。
概述
文档处理管线是 Paperless-ngx 的核心组件,它将输入的文档转换为系统中可搜索、已分类的条目。该管线处理的任务包括文本提取、OCR(光学字符识别)、条码检测、文档分离、元数据提取和自动分类。
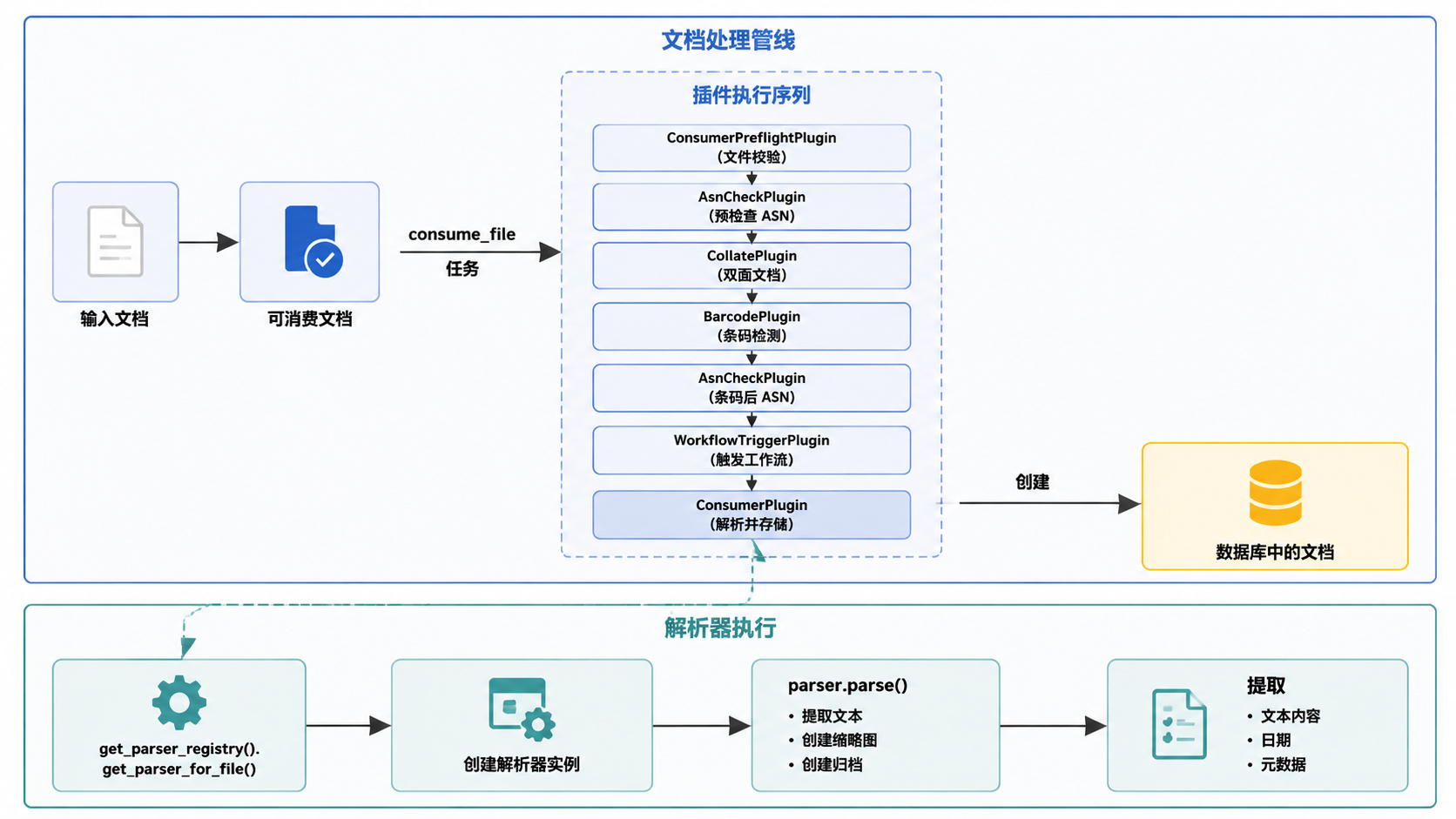
来源:src/documents/tasks.py:124-156, src/documents/consumer.py:214-345
文档解析器
文档处理首先根据输入文档的 MIME 类型选择合适的解析器。解析器在系统中注册,并根据其支持的 MIME 类型和权重进行选择。
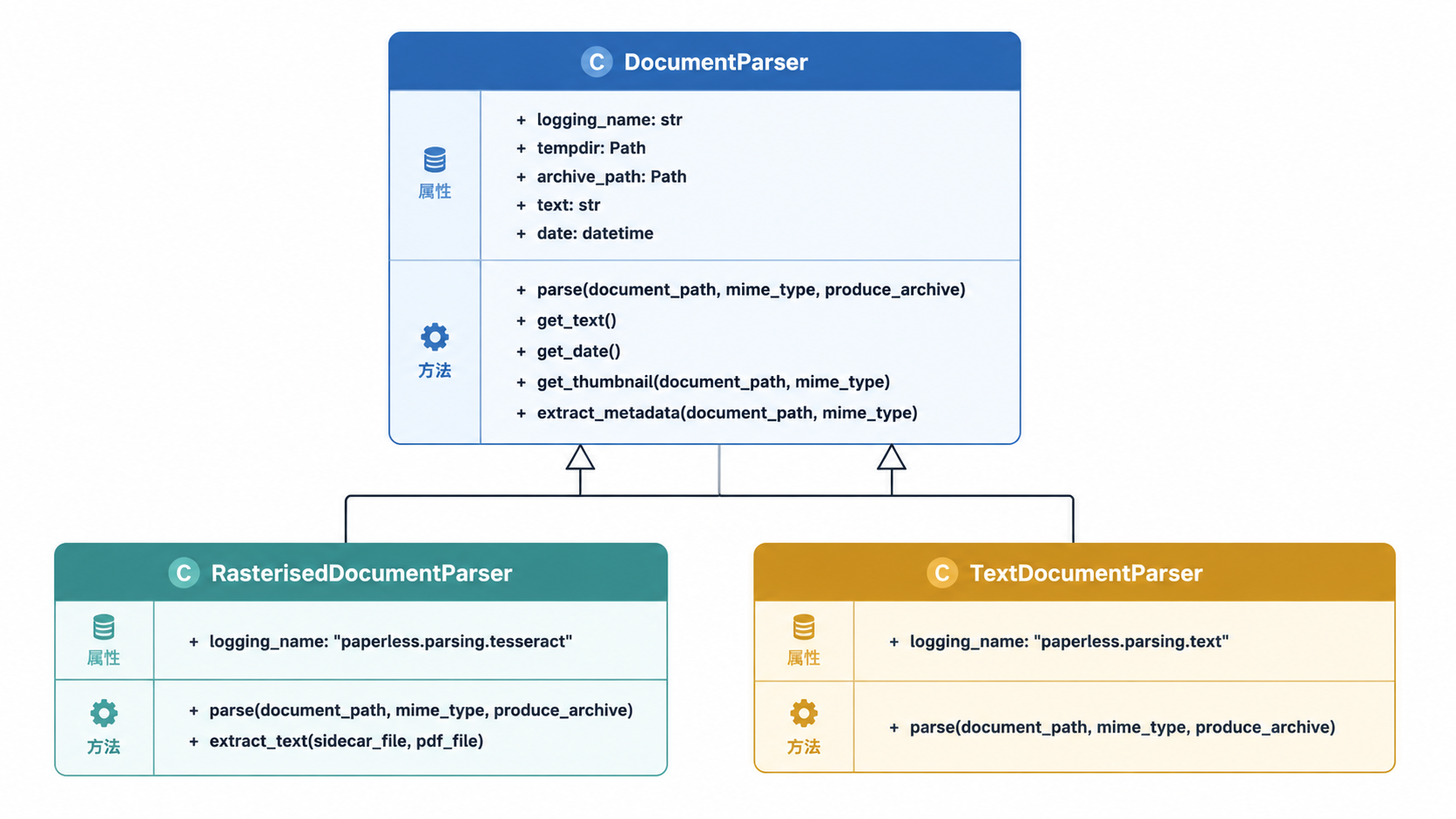
来源:src/documents/parsers.py:205-245, src/documents/consumer.py:124-188
解析器注册与选择
解析器通过 get_parser_registry() 工具识别,该工具会为给定的 MIME 类型找到评分最高的解析器。
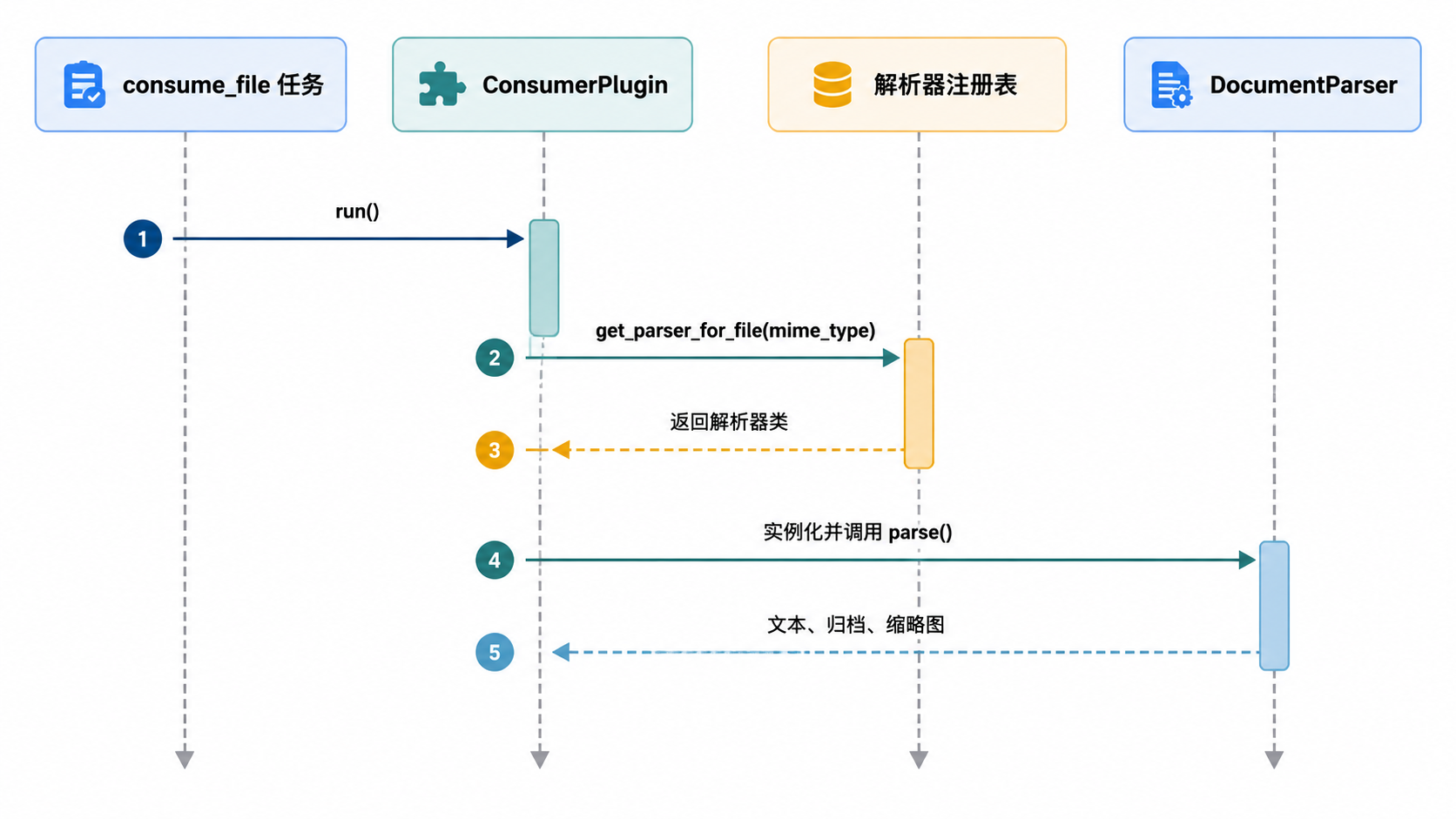
来源:src/documents/parsers.py:25-45, src/documents/consumer.py:214-345
Paperless-ngx 提供的主要解析器包括:
- RasterisedDocumentParser:使用 OCR(Tesseract)处理 PDF 和图像。
- TextDocumentParser:处理纯文本文档。
- TikaDocumentParser:在启用 Tika 集成时处理办公文档。
来源:src/documents/parsers.py:58-68, src/documents/consumer.py:158-184
处理管线执行
文档处理管线实现为一个名为 consume_file 的 Celery 任务。该任务通过按顺序执行一系列 ConsumeTaskPlugin 子类来编排整个流程。
1. 双面文档处理(CollatePlugin)
CollatePlugin 处理分两次扫描的双面文档。它会从指定的子目录中整理奇偶页,以恢复原始文档顺序。
来源:src/documents/tasks.py:149-153
2. 条码处理(BarcodePlugin)
BarcodePlugin 扫描文档中的条码,这些条码可以触发文档拆分、提取归档序列号(ASN)或分配标签。详细信息请参阅条码处理。
来源:src/documents/barcodes.py:60-100
3. 工作流触发处理(WorkflowTriggerPlugin)
WorkflowTriggerPlugin 检查是否存在匹配的、触发类型为 CONSUMPTION 的工作流。它允许工作流在文档最终确定之前覆盖文档元数据(如所有者、标签或通信方)。
来源:src/documents/consumer.py:67-87
4. 文档消费(ConsumerPlugin)
ConsumerPlugin 是管线的核心。它负责:
- 解析:调用选定的
DocumentParser。 - 日期提取:尝试从文本或文件名中查找文档的创建日期。
- 缩略图生成:创建视觉预览(通常为 WebP 格式)。
- 数据库存储:创建
Document模型实例。 - 分类:运行基于规则和基于机器学习的匹配,以确定元数据。
来源:src/documents/consumer.py:214-450
OCR 与文本提取
对于 PDF 和图像文档,文本提取通常由 OCRmyPDF 或 Tesseract 处理。系统根据 PAPERLESS_OCR_MODE 以及输入是否为“原生数字”PDF 来决定是否生成归档 PDF。详细信息请参阅OCR 与文本提取。
来源:src/documents/consumer.py:124-188
文档分类
文本提取完成后,系统使用 DocumentClassifier 分配元数据。这包括:
- 通信方:谁发送了文档。
- 文档类型:例如发票、信件。
- 标签:例如税务、工作。
- 存储路径:文件在磁盘上的存储位置。
详细信息请参阅文档分类。
来源:src/documents/signals/handlers.py:93-181
文件处理与存储
Paperless-ngx 在两个主要目录中管理文件:ORIGINALS_DIR 和 ARCHIVE_DIR。
- 文件名生成:系统使用
generate_filename和generate_unique_filename来确定路径,并遵循PAPERLESS_FILENAME_FORMAT或StoragePath模板。 - 唯一性约束:如果发生文件名冲突,会在名称后附加一个计数器(例如
_01)。 - 校验和:为原始文件和归档文件计算 SHA-256 校验和,以确保完整性并检测重复文件。
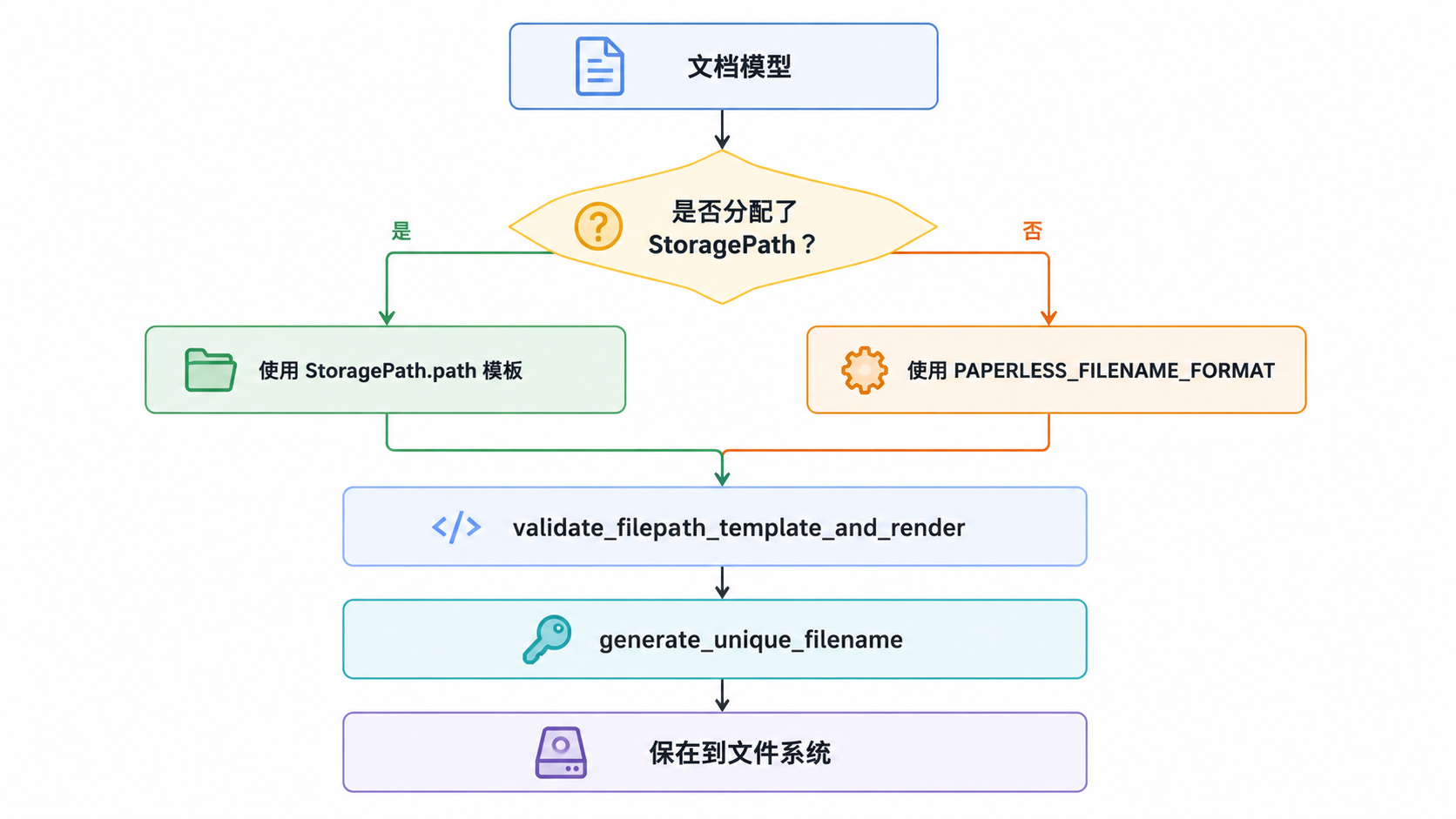
来源:src/documents/file_handling.py:44-100, src/documents/file_handling.py:125-185
健全性与完整性
系统包含一个 sanity_checker 模块,用于验证管线和存储的健康状况:
- 校验和验证:确保磁盘上的文件与数据库中的校验和一致。
- 孤儿文件检测:识别媒体文件夹中未被数据库跟踪的文件。
- 缺失文件报告:报告数据库中文件在磁盘上缺失的文档。
来源:src/documents/sanity_checker.py:38-145, src/documents/tasks.py:92-167