文档消费
文档入库
相关源文件
本章引用的主要源码文件:
paperless.conf.examplesrc/documents/admin.pysrc/documents/apps.pysrc/documents/consumer.pysrc/documents/file_handling.pysrc/documents/mail.pysrc/documents/management/commands/document_consumer.pysrc/documents/models.pysrc/documents/parsers.pysrc/documents/sanity_checker.pysrc/documents/signals/handlers.pysrc/documents/tasks.pysrc/documents/tests/conftest.pysrc/documents/tests/test_consumer.pysrc/documents/tests/test_file_handling.pysrc/documents/tests/test_management.pysrc/documents/tests/test_management_consumer.pysrc/documents/tests/test_sanity_check.pysrc/documents/tests/test_tasks.pysrc/documents/utils.py
文档入库是指文件被摄入 Paperless-ngx 系统、经过处理并转化为可搜索文档的过程。本页面将解释文档如何进入系统、如何处理文档,以及条码检测等功能如何影响入库流程。
关于入库后文档的处理方式,请参阅 OCR 与文本提取 和 文档分类。
入库来源
文档可以通过以下三种主要渠道进入 Paperless-ngx 系统:
| 来源 | 描述 |
|---|---|
| 入库文件夹 | 一个被监控的目录,放入其中的文件会被自动处理。 |
| 电子邮件 | 配置的邮件账户,会将附件转发到系统(邮件处理)。 |
| API/Web 上传 | 通过 Web 界面或 REST API 直接上传文件。 |
来源:src/documents/management/commands/document_consumer.py:1-7, src/documents/tasks.py:135-200, src/documents/data_models.py:1-50
文档入库流程
高层流程图
下图展示了文件从进入系统到最终存储的完整流程,并突出显示了涉及的具体代码实体。
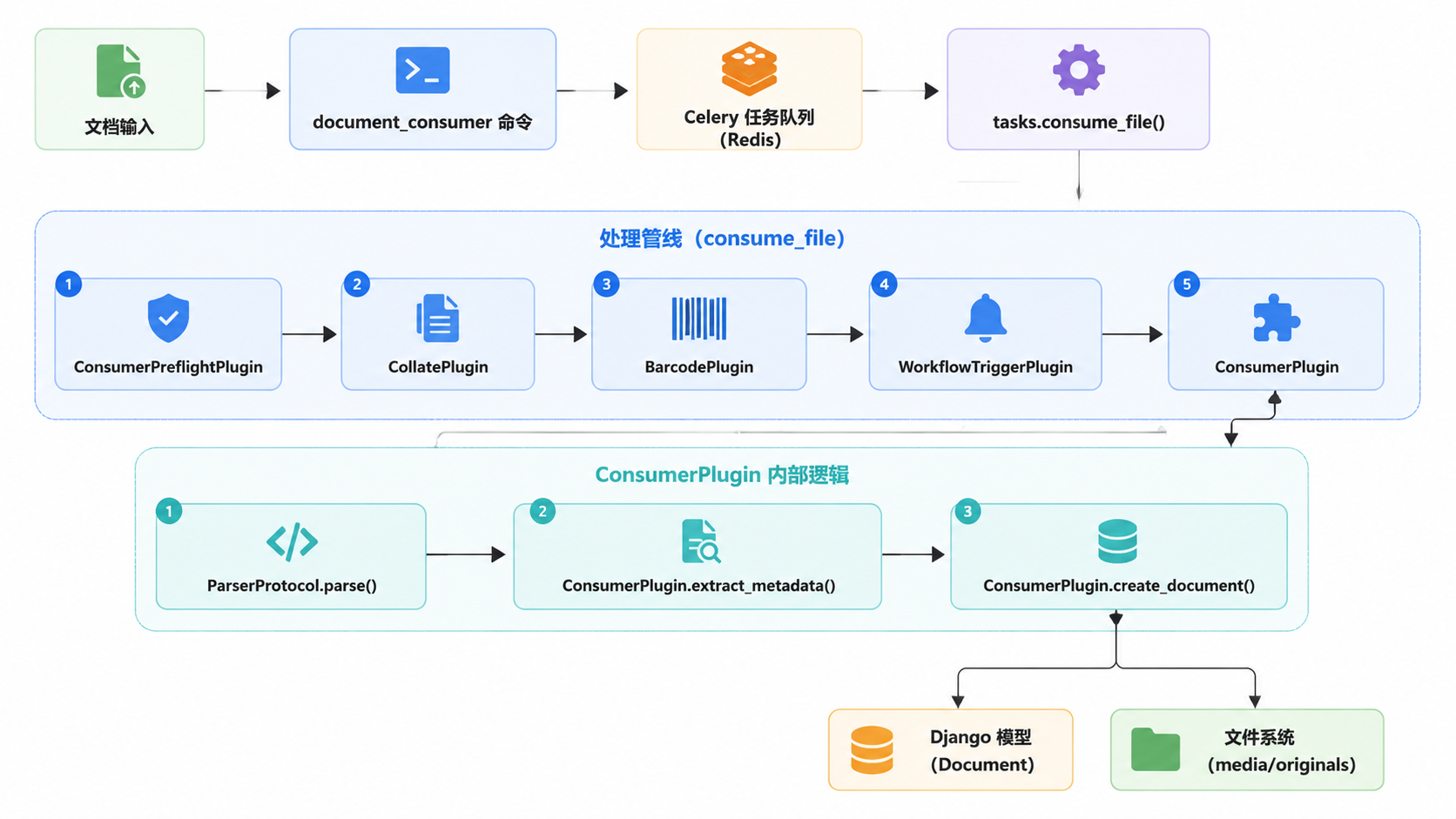
来源:src/documents/tasks.py:124-155, src/documents/consumer.py:40-60
入库任务
主要的入库流程由 consume_file Celery 任务处理 src/documents/tasks.py:124,该任务通过 plugins 列表中定义的一系列插件来处理文件 src/documents/tasks.py:140-155。
该任务使用 ProgressManager src/documents/plugins/helpers.py:1-50 通过 WebSocket 向前端报告状态 src/documents/tasks.py:158-161。
插件执行顺序:
- ConsumerPreflightPlugin:验证文件是否存在以及基本完整性
src/documents/consumer.py:1100。 - AsnCheckPlugin:(可选)验证提供的归档序列号(ASN)未被使用
src/documents/tasks.py:148。 - CollatePlugin:通过合并特定子目录中的文件来处理双面文档的整理
src/documents/double_sided.py。 - BarcodePlugin:检测并处理条码,用于拆分、ASN 分配或标签分配
src/documents/barcodes.py:60。 - WorkflowTriggerPlugin:执行
run_workflows,根据文档内容或属性应用元数据覆盖src/documents/consumer.py:67-88。 - ConsumerPlugin:核心插件,负责文件解析、OCR、缩略图生成和数据库记录创建
src/documents/consumer.py:300。
来源:src/documents/tasks.py:124-200, src/documents/consumer.py:67-88
文档消费者命令
document_consumer 管理命令使用 watchfiles 库监控入库目录中的新文件 src/documents/management/commands/document_consumer.py:25。
文件稳定性跟踪器
为防止在文件仍在写入时(例如,网络复制较慢时)处理文件,Paperless-ngx 使用 FileStabilityTracker src/documents/management/commands/document_consumer.py:75。
一个文件被认为稳定需满足以下条件:
- 其大小和修改时间(
mtime)在配置的延迟时间内保持不变src/documents/management/commands/document_consumer.py:148-157。 TrackedFile.is_unchanged()检查返回 truesrc/documents/management/commands/document_consumer.py:63-72。
入库逻辑
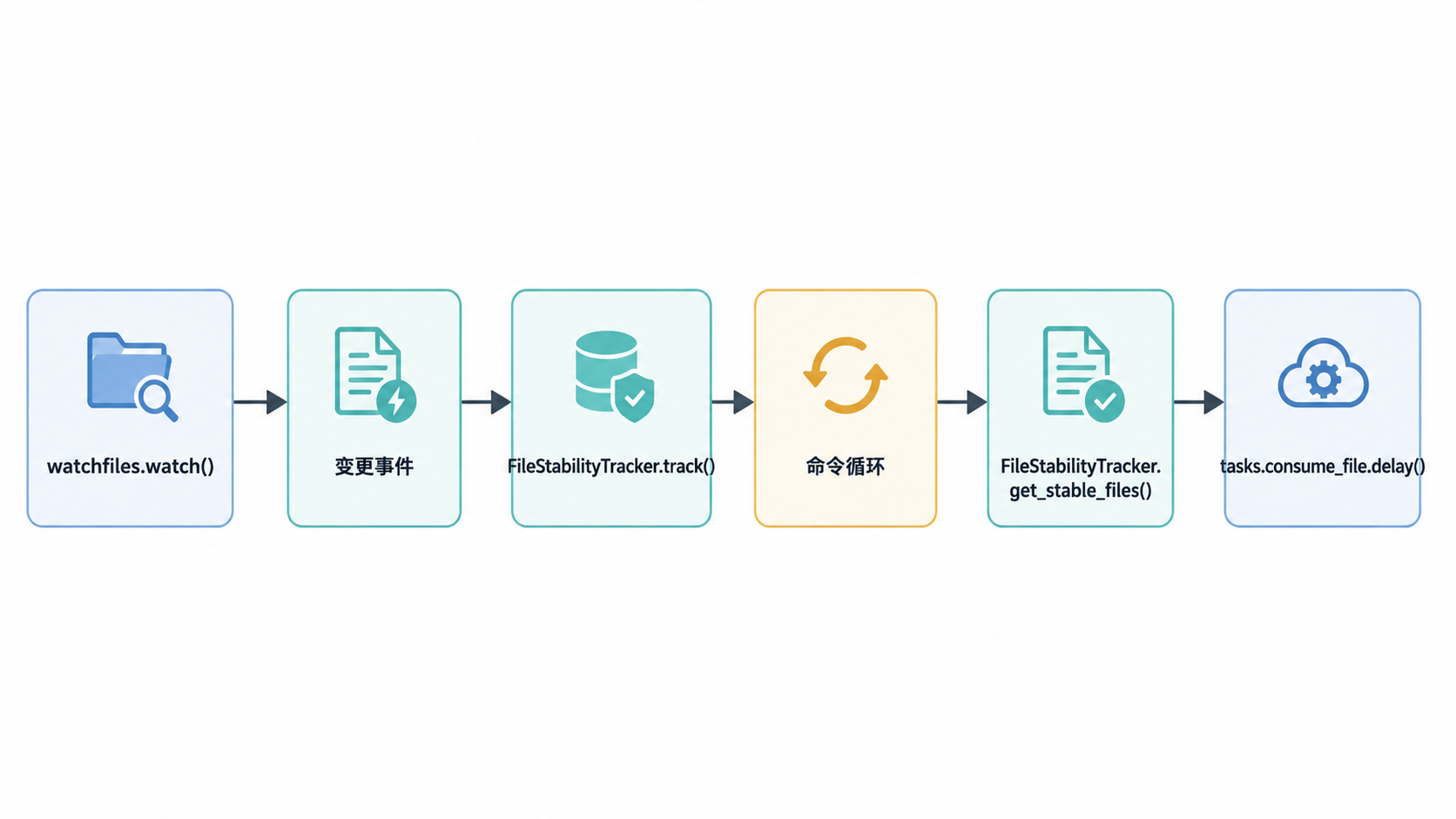
来源:src/documents/management/commands/document_consumer.py:75-180, src/documents/management/commands/document_consumer.py:280-310
文件过滤
ConsumerFilter 类 src/documents/management/commands/document_consumer.py:182 决定哪些文件应被忽略。它排除以下文件:
- 标准系统文件,如
.DS_Store或Thumbs.dbsrc/documents/management/commands/document_consumer.py:197-203。 - 不匹配通过
get_supported_file_extensions()获取的支持扩展名的文件src/documents/management/commands/document_consumer.py:236。
来源:src/documents/management/commands/document_consumer.py:182-240
条码处理
BarcodePlugin src/documents/barcodes.py:60 通过扫描文档的前几页(由 PAPERLESS_CONSUMER_BARCODE_MAX_PAGES 配置)提供高级摄入功能。
条码功能
| 功能 | 描述 | 实现 |
|---|---|---|
| 拆分 | 当检测到特定的分隔条码(默认为 PATCHT)时,将 PDF 拆分为多个文档。 | BarcodePlugin.separate_pages() src/documents/barcodes.py:389 |
| ASN 分配 | 从具有特定前缀(默认为 ASN)的条码中提取数字归档序列号。 | BarcodePlugin.asn 属性 src/documents/barcodes.py:308 |
| 标签分配 | 使用正则表达式将条码值映射到特定的 Paperless 标签。 | BarcodePlugin.tags 属性 src/documents/barcodes.py:343 |
检测实现
该插件使用 pyzbar 或 zxing 扫描图像 src/documents/barcodes.py:221-225。如果提供的是 PDF,则会先使用 pdf2image 以特定 DPI 将其转换为图像 src/documents/barcodes.py:246-252。
来源:src/documents/barcodes.py:60-468
存储与路径解析
文档入库后,其在 media/originals 目录中的位置由 generate_filename 函数决定 src/documents/file_handling.py:125。
文件名生成
系统按以下优先级确定文件路径:
- StoragePath 模型:如果文档匹配某个
StoragePath规则,则使用其模板src/documents/file_handling.py:143。 - 全局格式:如果设置了
PAPERLESS_FILENAME_FORMAT,则将其作为后备方案src/documents/file_handling.py:145。 - 默认:如果未提供格式,文档将存储为
{id:07d}.{ext}src/documents/file_handling.py:180-183。
重复检测
在创建新文档之前,ConsumerPlugin 会计算文件的 MD5 校验和 src/documents/consumer.py:400。如果已存在具有相同校验和的文档,则会中止入库并抛出 ConsumeFileDuplicateError src/documents/consumer.py:94,除非通过配置明确允许重复。
来源:src/documents/file_handling.py:125-186, src/documents/consumer.py:390-410